1. build
uDeviceX uses a wrapper u.make for building the source.
This allows to load modules when needed.
1.1. verbosity
The verbosity can be controlled during the compilation process:
Shows full compilation and linking commands:
u.make LOG=Profile compilation time:
u.make LOG='@time -f "%e $<"'Hide compilation messages:
u.make LOG=@1.2. Arch Linux
u.make MPI_VARIANT=ompi-cxx HDF5_CXXFLAGS= HDF5_LIBS=-lhdf5 NVCC_LIBS=-L/opt/cuda/lib64
or
MAKEFLAGS="MPI_VARIANT=ompi-cxx HDF5_CXXFLAGS= HDF5_LIBS=-lhdf5 NVCC_LIBS=-L/opt/cuda/lib64" \ u.test test/compile
1.3. dependencies
Dependencies must be generated after adding a file or changing includes.
Run from src/ directory:
../tools/deps
2. coding conventions
2.1. modules
uDeviceX consists of modules. Modules are as independant as possible. They consist of a folder with one or more compilation units, and an interface. Whenever it is possible, the structures are hidden from the client of the module.
2.2. naming
2.2.1. variables
-
names of local variables are short and understandable from the context
-
names of global variables are as descriptive as possible
-
arrays of simple structures
xhave namesxx, eg.ppis an array of particles,ccis an array of colors,iiis an array of indices * array of small dimentionality may use an enum type for readability, e.g.
enum {X, Y, Z};
int r[3];
r[X] = rx;
r[Y] = ry;
r[Z] = rz;2.2.2. functions
-
a function name is descriptive on its own or inside a module.
-
arguments are ordered as follow:
-
input is at the beginning
-
input/output come after input and start with a commented
io -
output comes after input/output and start with a comment or
odepending on the context -
sizes have higher priority than arrays
-
workspace comes at the end ans starts with a commented
w
-
-
do not use references, use pointers instead
Example of valid function declarations:
void read_int_from_file(const char *fname, /**/ int *n, int *ii);
void forward_euler(int n, const Force *ff, /* io */ Particle *pp);Function names part of a module interface start with the module name.
Functions private to a module do not need to contain the module name
if the context make it clear. Use the static qualifier for functions
with compilation-unit scope.
2.3. file structure
-
no include guards; no "headers in headers" if easily avoidable
-
all cuda kernels are in a separate header
.hfile -
a module is implemented inside its own directory
A-
it has its own object
A/imp.cuorA/imp.cpp(.cppprefered if possible) -
interface
A/imp.h -
implementation can be done in separate files inside
A/imp/directory -
internal cuda (private to module) code are inside
A/dev/directory -
cuda interface inside
A/dev.h(for client use)
-
-
modules can have submodules, which follow the same structure as above, e.g. submodule
Binside moduleAbelongs toA/B/directory
2.4. style
for emacs: the following c++ mode is used
(defun u/c-indent-common ()
(setq c-basic-offset 4
indent-tabs-mode nil))
(defun u/c++-indent ()
(u/c-indent-common)
(c-set-offset 'innamespace [0]))
(defun u/c-indent () (u/c-indent-common))
(add-hook 'c-mode-hook 'u/c-indent)
(add-hook 'c++-mode-hook 'u/c++-indent)
(setq c-default-style
'((java-mode . "java")
(awk-mode . "awk")
(c-mode . "k&r")
(cc-mode . "k&r")))
(add-to-list 'auto-mode-alist '("\\.cu\\'" . c++-mode))
(add-to-list 'auto-mode-alist '("\\.h\\'" . c++-mode))3. documentation
The uDeviceX documentation is written in Asciidoc format and converted to html.
This operation requires asciidoctor (converter to html) and
pygments.rb (for code highlighting).
3.1. installation
3.1.1. Mac OS X
gem install asciidoctor
gem install pygments.rb3.1.2. Arch linux
sudo pacman -S asciidoctor
gem install pygments.rb3.2. build
When writing documentation, it is useful to build it and view it on a local server.
From doc/:
./tools/start (1)
./tools/view (2)
./tools/stop (3)| 1 | start a local server (to be done only once) |
| 2 | open the main page in browser from local server |
| 3 | stop the local server |
./configure (1)
make -j (2)| 1 | make dependencies (to be run after adding a file to documentation) |
| 2 | build documentation for local server |
3.3. Deploy
The deploy command cleans, builds and pushes the documentation on
github pages https://github.com/amlucas/udoc.
The commit message on the udoc repository points on the current
uDeviceX commit. It is preferable to have a clean local repository
before deploying:
git clean -xdf
./tools/deploy4. algo: algorithm helpers
4.1. edg: mesh edge data
Set and get val on edges of the mesh.
void edg_ini(int md, int nv, int *hx);
void edg_set(int md, int i, int j, int val, /**/ int *hx, int *hy); (1)
int edg_get(int md, int i, int j, const int *hx, const int *hy); (2)
int edg_valid(int md, int i, int j, const int *hx); (3)| 1 | set val |
| 2 | get val |
md is a maximum degree, nv number of vertices, h[xy] storage of
size nv*md.
4.2. Kahan summation
Summation stable to numerical error.
void kahan_sum_ini(/**/ KahanSum**);
void kahan_sum_fin(KahanSum*);
void kahan_sum_add(KahanSum*, double input); (1)
double kahan_sum_get(const KahanSum*); (2)
double kahan_sum_compensation(const KahanSum*); (3)| 1 | add input to the sum |
| 2 | return current sum |
| 3 | return current value of compensation for diagnostic |
Example:
kahan_sum *k;
kahan_sum_ini(&k);
for (i = 0; i < n; i ++)
kahan_sum_add(kahan_sum, a[i]);
sum = kahan_sum_get(kahan_sum);
kahan_sum_fin(k);4.3. minmax
compute extends of chunks of particles
-
input is an array of particles, the number of chunks and the number of particles per chunk.
-
output is the bounding box in for each chunk of particles.
4.3.1. example
Consider the simple case on 1D:
input: particles positions: 0.1 0.5 0.2 0.3 1.2 1.0 number of chunks: 2 number of particles per chunk: 3 output: min: 0.1 0.3 max: 0.5 1.0
4.3.2. interface
void minmax(const Particle *pp, int nv, int nobj, /**/ float3 *lo, float3 *hi);4.4. scan: prefix sum
exclusive prefix sum implementation for integer data
input is of size n, output is of size n + 1 as in the following
example:
input: 4 5 1 2 3 - output: 0 4 9 10 12 15
4.4.1. interface
void scan_apply(const int *input, int size, /**/ int *output, /*w*/ Scan*); (1)
void scan_ini(int size, /**/ Scan**); (2)
void scan_fin(Scan*); (3)| 1 | perform scan operation on input of size size |
| 2 | allocate workspace for performing scan of size size |
| 3 | free workspace |
4.5. Scalars
A read-only wrapper to provide uniform accsses to an array n
scalars.
void scalars_float_ini(int n, const float*, /**/ Scalars**);
void scalars_double_ini(int n, const double*, /**/ Scalars**);
void scalars_vectors_ini(int n, const Vectors*, int dim, /**/ Scalars**);
void scalars_zero_ini(int n, /**/ Scalars**);
void scalars_one_ini(int n, /**/ Scalars**);
void scalars_fin(Scalars*);
double scalars_get(const Scalars*, int i);See also Vectors.
4.6. Vectors
A read-only wrapper to provide uniform accsses to an array n vectors
of size three. The module does not copy data.
void vectors_float_ini(int n, const float*, /**/ Vectors**); (1)
void vectors_postions_ini(int n, const Particle*, /**/ Vectors**); (2)
void vectors_postions_edge_ini (const Coords*, int n, const Particle*, /**/ Vectors**); (3)
void vectors_postions_center_ini(const Coords*, int n, const Particle*, /**/ Vectors**); (4)
void vectors_velocities_ini(int n, const Particle*, /**/ Vectors**); (5)
void vectors_zero_ini(int n, /**/ Vectors**); (6)
void vectors_fin(Vectors*);
void vectors_get(const Vectors*, int i, /**/ float r[3]); (7)| 1 | array of float packed as x0 y0 z0 x1 y1 z1 |
| 2 | particle positions |
| 3 | particle positions relative to domain edge |
| 4 | particle positions relative to domain center |
| 5 | particle velocity |
| 6 | array of zeros |
| 7 | return a vector i |
Example,
#define n 2
Vectors *pos;
float r[3], data[3*n] = {1, 2, 3, 4, 5, 6};
vectors_float_ini(n, data, &pos);
vectors_get(pos, 1, /**/ r);
vectors_fin(pos);See also Scalars.
4.7. utils
helper device functions
Warp reduction: sum all elements within a warp. This is a collective operation, all threads of the warp must execute it.
template <typename T>
_I_ T warpReduceSum(T v) (1)
_I_ float2 warpReduceSum(float2 val) (2)
_I_ float3 warpReduceSum(float3 val) (3)| 1 | generic warp reduction. thread 0 of the warp gets the result. |
| 2 | specific implementation for float2 |
| 3 | specific implementation for float3 |
5. clist
Helpers to find which particles are in a given cell.
-
reorder data according to particle positions into cells
-
access particles within a given cell
5.1. example
consider a 1D example of particles with positions in domain [0, 4)
pp: 2.5 0.1 1.1 0.5 1.6
After cell list building (we take 1 as cell size), the above data becomes
pp: 0.1 0.5 1.1 1.6 2.5 - cc: 2 2 1 0 ss: 0 2 4 5
where pp is the particle array, cc (counts) is the number of particles per
cell and ss (starts) is the prefix sum of cc.
Accessing all particles in cell i=1 ([1,2)) can be done as follows:
loop: j = 0, ..., cc[i]
id = ss[i] + j
p = pp[id]
work(p)The above can be easily extended in 3D, only ordering changes.
5.2. data structures
5.2.1. Clist
struct Clist {
int3 dims;
int ncells;
int *starts, *counts;
};-
dimsdimensions of the grid -
ncellsnumber of cells -
countsnumber of particles per cell -
startsexclusive prefic scan of the above
5.2.2. Map
Helper to build the cell lists (hidden from client)
struct ClistMap {
int nA; /* number of source arrays to build the cell lists, e.g remote+bulk -> 2 */
uchar4 **ee; /* cell entries */
uint *ii; /* codes containing: indices of data to fetch and array id from which to fetch */
Scan *scan; /* scan workspace */
long maxp; /* maximum number of particles per input vector */
};-
nAnumber of source arrays -
eecell entries: one array per source array, containing a list ofuchar4with entries (xcid,ycid,zcid,sid)-
xcid: x cordinate of the cell, in 0, …,dims.x -
ycid: y cordinate of the cell, in 0, …,dims.y -
zcid: z cordinate of the cell, in 0, …,dims.z -
sid: source array id, in 0, …,nA
-
-
iiindices of particles to fetch. can be decoded into the source array id and the particle id inside this array -
scanscan workspace, see scan
5.3. interface
allocate/deallocate
void clist_ini(int LX, int LY, int LZ, /**/ Clist **c);
void clist_fin(/**/ Clist *c);
void clist_ini_map(int maxp, int nA, const Clist *c, /**/ ClistMap **m);
void clist_fin_map(ClistMap *m);build interface:
void clist_ini_counts(Clist *c);
void clist_subindex(bool project, int aid, int n, const PartList lp, /**/ Clist *c, ClistMap *m);
void clist_build_map(const int nn[], /**/ Clist *c, ClistMap *m);
/* special for fluid distribution */
void clist_subindex_local(int n, const PartList lp, /**/ Clist *c, ClistMap *m);
void clist_subindex_remote(int n, const PartList lp, /**/ Clist *c, ClistMap *m);
void clist_gather_pp(const Particle *pplo, const Particle *ppre, const ClistMap *m, long nout, /**/ Particle *ppout);
void clist_gather_ii(const int *iilo, const int *iire, const ClistMap *m, long nout, /**/ int *iiout);
/* quick cell build for single array */
void clist_build(int nlo, int nout, const Particle *pplo, /**/ Particle *ppout, Clist *c, ClistMap *m);The fields can be accessed from
const int* clists_get_ss(const Clist *c);
const int* clists_get_cc(const Clist *c);
int3 clists_get_dim(const Clist *c);
int clists_get_n(const Clist *c);
const uint* clist_get_ids(const ClistMap *m);Device interface: code/decode map ids
_I_ uint clist_encode_id(int s, int pid)
_I_ void clist_decode_id(uint c, /**/ int *s, int *pid)5.4. algorithm
The cell build process is linear in number of particles np and n log(n)
in number of cells n.
The process to build cell lists is as follows:
- build ee and counts: O(np) - set counts[i] = 0 for all i - for each particle, compute its cell id cid - get unique subindex k within the cell by updating cc[cid] - scan counts to get starts O(nlog n) - construct ii: O(np) - for each particle with id i, compute new index j = ss[cid] + k[i] - set ii[j] = i - Gather data: O(np) - new particle vector pp1 from pp: pp1[i] = pp[ii[i]]
6. cnt: contact forces
contact interactions between objects (rigid objects, rbc membranes)
6.1. interface
allocate/deallocate
void cnt_ini(int maxp, int rank, int3 L, int nobj, /**/ Contact **c);
void cnt_fin(Contact *c);computing forces:
void cnt_build_cells(int nw, const PairParams **prms, const PaWrap *pw, /**/ Contact *c); (1)
void cnt_bulk(const Contact *cnt, int nw, const PairParams **prms, PaWrap *pw, FoWrap *fw); (2)
void cnt_halo(const Contact *cnt, int nw, const PairParams **prms, PaWrap *pw, FoWrap *fw, Pap26 all_pp, Fop26 all_ff, const int *all_counts); (3)| 1 | build cell lists for local objects |
| 2 | compute the interactions between local objects particles |
| 3 | compute the interactions between local and remote objects particles |
7. color
7.1. purpose
Each particle of the solvent has an assigned color when the
multi_solvent flag is enabled.
It is helpful for modeling different solvent with different
viscosities, surface tensions etc.
7.2. modules
Some utility modules are implemeted in /src/color.
7.2.1. flux
recolor particles crossing the face of the periodic domain in the positive direction x, y or z
struct int3;
struct Particle;
struct Coords;
struct Rnd;
void color_linear_flux(const Coords*, int3 L, int dir, int color, int n, const Particle *pp, /**/int *cc);
void color_tracers(const Coords *coords, int color, const float R, const float Po, int n, const Particle *pp, int *cc);
void decolor_tracers(const Coords *coords, int color, const float R, const float Po, int n, const Particle *pp, int *cc);
void tracers_ini(const int n);
void tracers_fin();-
diris the direction x, y or z -
coloris the new color -
ppare input particles of sizen -
ccare output colors (stay the same if does not cross the face)
8. comm: generic communicator
generic communicator with neighboring ranks (halo).
8.1. purpose
Communicate data with the neighboring ranks
8.2. data structures
hBags: buffers on the host, contains all necessary information of the data to communicate:
struct hBags {
data_t *data[NBAGS]; /* data on the host */
int *counts; /* size of the data */
int capacity[NBAGS]; /* capacity of each frag (elem number) */
size_t bsize; /* size of one datum in bytes */
};dBags: buffers on the device
struct dBags {
data_t *data[NBAGS]; /* data on the device */
};CommBuffer: wrapper to serialize hBags data. Hidden from user.
Comm: contains the communication related variables. It is hidden
from user.
8.3. allocation mod
User can choose how the buffers are allocated with the enum type AllocMod.
This is used in the function ini and fin. allocation mode and free mode are assumed to be the same
currently supported allocation modes:
HST_ONLY, /* only host bags allocated */
DEV_ONLY, /* only device bags allocated */
PINNED, /* both host and device pinned */
PINNED_HST, /* host pinned; no device memory */
PINNED_DEV, /* host pinned; device global memory on gpu */
NONE /* no allocation */8.4. interface
8.4.1. memory management
void comm_bags_ini(AllocMod fmod, AllocMod bmod, size_t bsize, const int capacity[NBAGS], /**/ hBags *hb, dBags *db);
void comm_bags_fin(AllocMod fmod, AllocMod bmod, /**/ hBags *hb, dBags *db);
void comm_ini(MPI_Comm cart, /**/ Comm **c);
void comm_fin(/**/ Comm *c);
void comm_buffer_ini(int nbags, const hBags *hbb, CommBuffer**);
void comm_buffer_fin(CommBuffer*);-
bags alloc: Given two structures
hBagsanddBags,iniallocates the buffers on host and device.iniexpects 2 allocation modes:-
fmod: allocation mode for fragment buffers -
bmod: allocation mode for bulk buffer
-
-
comm alloc: initialize
Commstructure -
comm_buffer: initialize from bags capacities.
8.4.2. communication
Communication happens between host bags (see hBags structure).
It needs 3 entities:
-
receiver bags
-
sender bags
-
a
Commfor communicating through MPI
The interface is as follows:
void comm_post_recv(hBags *b, Comm *c); (1)
void comm_post_send(const hBags *b, Comm *c); (2)
void comm_wait_recv(Comm *c, /**/ hBags *b); (3)
void comm_wait_send(Comm *c); (4)| 1 | call MPI asynchronous recv and store requests in s |
| 2 | call MPI asynchronous send and store requests in s |
| 3 | wait for recv requests |
| 4 | wait for send requests |
For more than one bags, it is recommanded to use the CommBuffer structure to group the messages into one:
void comm_post_recv(CommBuffer *cb, Comm *c);
void comm_post_send(const CommBuffer *cb, Comm *c);
void comm_wait_recv(Comm *c, /**/ CommBuffer *cb);
void comm_wait_send(Comm *c);8.4.3. getters
Convenient get functions:
int comm_get_number_capacity(int i, const hBags *b); (1)
size_t comm_get_byte_capacity(int i, const hBags *b); (2)| 1 | get the number of elements (not bytes) that can be stored in the
fragment i of the bag |
| 2 | get the number of bytes that can be stored in the
fragment i of the bag |
Convert data from bag to static array:
template <typename BAGT, typename T, int N>
static void bag2Sarray(BAGT bags, Sarray<T*, N> *buf)9. conf: runtime configuration
9.1. purpose
-
wrapper for the
libconfiglibrary -
holds configurations from 4 sources:
-
set by program (priority 4)
-
arguments (priority 3)
-
configuration file (priority 2)
-
default parameters (priority 1)
-
When retrieving a value, the source with higher priority is used. If not found in a source, the value is retrieved from the next highest priority. If no source contains the parmeter, an error is raised.
9.2. data structure
enum {
EXE, /* from program setters */
ARG, /* from arguments */
OPT, /* from additional file */
DEF, /* from default file */
NCFG
};
struct Config {
config_t c[NCFG];
config_t *r; /* what have been read */
};Consists of an array of config_t descriptors, ordered by priority.
Indices correspond to the enum keys.
The first key has the highest priority, second key has second highest
priority etc.
The r field is the configuration history, i.e what is read by the program.
9.3. interface
Allocate and free the structure:
void conf_ini(/**/ Config **c);
void conf_fin(/**/ Config *c);Read data from the default, optional and command line config:
void conf_read(int argc, char **argv, /**/ Config *cfg);Lookup variables from the configuration:
void conf_lookup_int(const Config *c, const char *desc, int *a);
void conf_lookup_float(const Config *c, const char *desc, float *a);
void conf_lookup_bool(const Config *c, const char *desc, int *a);
void conf_lookup_string(const Config *c, const char *desc, const char **a);
void conf_lookup_vint(const Config *c, const char *desc, int maxn, int *n, int a[]);
void conf_lookup_int3(const Config *c, const char *desc, int3 *a);
void conf_lookup_vfloat(const Config *c, const char *desc, int maxn, int *n, float a[]);
void conf_lookup_float3(const Config *c, const char *desc, float3 *a);
void conf_lookup_vstring(const Config *c, const char *desc, int maxn, int *n, const char **ss);Note that the program raises an error if the argument is not found or if an error occured (e.g. wrong type).
A convenient set of functions to look for variable in a given namespace:
void conf_lookup_int_ns(const Config *c, const char *ns, const char *desc, int *a);
void conf_lookup_float_ns(const Config *c, const char *ns, const char *desc, float *a);
void conf_lookup_bool_ns(const Config *c, const char *ns, const char *desc, int *a);
void conf_lookup_string_ns(const Config *c, const char *ns, const char *desc, const char **a);
void conf_lookup_vint_ns(const Config *c, const char *ns, const char *desc, int maxn, int *n, int a[]);
void conf_lookup_int3_ns(const Config *c, const char *ns, const char *desc, int3 *a);
void conf_lookup_vfloat_ns(const Config *c, const char *ns, const char *desc, int maxn, int *n, float a[]);
void conf_lookup_float3_ns(const Config *c, const char *ns, const char *desc, float3 *a);
void conf_lookup_vstring_ns(const Config *c, const char *ns, const char *d, int maxn, int *n, const char **ss);Lookup variables from the configuration:
bool conf_opt_int(const Config *c, const char *desc, int *a);
bool conf_opt_float(const Config *c, const char *desc, float *a);
bool conf_opt_bool(const Config *c, const char *desc, int *a);
bool conf_opt_string(const Config *c, const char *desc, const char **a);
bool conf_opt_vint(const Config *c, const char *desc, int maxn, int *n, int a[]);
bool conf_opt_int3(const Config *c, const char *desc, int3 *a);
bool conf_opt_vfloat(const Config *c, const char *desc, int maxn, int *n, float a[]);
bool conf_opt_float3(const Config *c, const char *desc, float3 *a);
bool conf_opt_vstring(const Config *c, const char *desc, int maxn, int *n, const char **ss);The program does not raise error if the variable is not found.
The return value is true if the variable has been found and false
otherwise.
The client may overwrite variables in the config object:
void conf_set_int(const char *desc, int a, Config *c);
void conf_set_vint(const char *desc, int nelem, const int a[], Config *cfg);
void conf_set_int3(const char *desc, int3 a, Config *cfg);
void conf_set_float(const char *desc, float a, Config *cfg);
void conf_set_vfloat(const char *desc, int nelem, const float a[], Config *cfg);
void conf_set_float3(const char *desc, float3 a, Config *cfg);
void conf_set_bool(const char *desc, int a, Config *cfg);
void conf_set_string(const char *desc, const char *a, Config *cfg);desc contains the names of the nested groups. separated by a . or
a /.
Example:
const char *desc = "main.sub.a";will correspond to
main = {
sub = {
a = ...
}
}The configuration can be dumped by using
void conf_write_exe(const Config *cfg, FILE *stream); (1)
void conf_write_history(const Config *cfg, FILE *stream); (2)| 1 | dump the fields set by the program to a stream |
| 2 | dump the fields read by the program to a stream |
10. Control
-
velocity controller
-
open boundary conditions
-
density controller
10.1. Velocity controller
control velocity by modifying the imposed hydrostatic force the force is modified using a PID controller https://en.wikipedia.org/wiki/PID_controller.
10.1.1. Controlled variables
The controlled variable is the (global) body force value. The state of the system is represented by
where \(( \mathbf{r_i}, \mathbf{v_i})\) are the \(i^{th}\) particle position and velocity, \(n\) is the number of particles and \(\mathbf{f}\) is a given transformation.
There is therefore 3 (independant) controlled variables.
the transformation is the way of averaging the velocity:
cartesian transformation keeps the velocity and does not depends on position:
radial transformation returns the velocity in polar coordinates
scaled by the radial position. the z component corresponds to
cartesian transformation:
with \(r = \sqrt{x^2 + y^2}\) and \(\theta = \arctan(y/x)\). \(x\) and \(y\) are particle position with respect to the center of the domain.
10.1.2. interface
allocate, deallocate:
void vcont_ini(MPI_Comm comm, int3 L, /**/ PidVCont **c);
void vcont_fin(/**/ PidVCont *cont);set the parameters (to be done only once, before any other calls):
void vcont_set_params(float factor, float Kp, float Ki, float Kd, /**/ PidVCont *c); (1)
void vcont_set_target(float3 vtarget, /**/ PidVCont *c); (2)
void vcont_set_cart(/**/ PidVCont *c); (3)
void vcont_set_radial(/**/ PidVCont *c); (4)| 1 | set the PID control variables. factor scales variables Kp, Ki`
and Kd |
| 2 | set the target velocity (in transformed space) |
| 3 | set the transformation mode to cartesian |
| 4 | set the transformation mode to radial |
The parameters can also be set through the configuration file:
void vcont_set_conf(const Config *cfg, /**/ PidVCont *c);By default, the state of the controller is set to zero current velocity. It can also be set throught the restart mechanism:
void vcont_strt_dump(MPI_Comm, const char *base, int id, const PidVCont*); (1)
void vcont_strt_read( const char *base, int id, PidVCont*); (2)| 1 | dump the state of the controller to a text file |
| 2 | read the state from a text file |
Control operations:
void vcont_sample(const Coords *coords, int n, const Particle *pp, const int *starts, const int *counts, /**/ PidVCont *c); (1)
float3 vcont_adjustF(/**/ PidVCont *c); (2)
void vcont_log(const PidVCont *c); (3)| 1 | get average velocity according to transformation and store it |
| 2 | reduce sampled quantities and update the controller. return the force |
| 3 | logging informations; dumped into the file vcon.txt |
10.1.3. configuration
syntax:
vcon = {
active = true
type = "cart" # can be also "rad"
U = [1.0, 1.0, 0.0] # target velocity in transformed space
factor = 0.08
Kp = 2.0
Ki = 1.0
Kd = 8.0
log_freq = 500
adjust_freq = 500
sample_freq = 1
}10.2. Inflow
Mass rate inflow.
Create particles given a surface \(S(u, v)\), with a velocity profile \(\mathbf{U}(u,v)\) with \((u,v) \in (0,1) \times (0,1)\).
10.2.1. Method
Define "cumulative inflow" \(\phi(u, v)\) in a bin of area \(dA \in S\).
Updated as follow:
where \(\rho\) is the number density.
When \(\phi \geq 1\), a particle is released at the bin position with random velocity \(\mathcal{N} (\mathbf{u}, k_BT)\). We also set \(\phi \leftarrow \phi - 1\).
10.2.2. interface
allocate, deallocate:
void inflow_ini(int2 nc, Inflow **i);
void inflow_fin(Inflow *i);initialize the inflow structure (to be done only once):
void inflow_ini_velocity(Inflow *i);
void inflow_ini_params_plate(const Coords *c, float3 o, int dir, float L1, float L2,
float3 u, bool upoiseuille, bool vpoiseuille,
/**/ Inflow *i);
void inflow_ini_params_circle(const Coords *c, float3 o, float R, float H, float u, bool poiseuille,
/**/ Inflow *i);depending on the type of inflow, call the appropriate
ini_params_xxx.
ini_velocity must be called after initializing the parameters.
it is used to setup the inlet velocity from parameters.
initialize from config parameters:
void inflow_ini_params_conf(const Coords *coords, const Config *cfg, /**/ Inflow *i);create particles (at every time step):
void inflow_create_pp(float kBT, int numdensity, float dt, Inflow *i, int *n, Particle *pp); (1)
void inflow_create_pp_cc(float kBT, int numdensity, float dt, int newcolor, Inflow *i, int *n, Particle *pp, int *cc); (2)| 1 | add particles to the array pp and increase n accordingly |
| 2 | same as above, with colors cc set to color |
10.2.3. configuration
plate
syntax for a 8.0 x 16.0 plate perpendicular to the x axis passing by
the point (1, 2, 3):
inflow = {
active = true
type = "plate"
L1 = 1.0
L2 = 16.0
direction = 0 # [0,1,2] = [X,Y,Z]
origin = [1.0, 2.0, 3.0]
upoiseuille = false # true for parabolic profile along L1
vpoiseuille = false # true for parabolic profile along L2
u = [10.0, 0.0, 0.0]
}circle
syntax for cylindrical surface:
inflow = {
active = true
type = "circle"
R = 1.0 # radius
H = 16.0 # hight of the cylinder
U = 1.0 # maximum velocity
center = [8.0, 8.0, 8.0]
poiseuille = false # parabolic profile along H if true
}10.3. Outflow
Delete particles satisfying a predicate
10.3.1. interface
allocate, deallocate:
void outflow_ini(int maxp, /**/ Outflow **o);
void outflow_fin(/**/ Outflow *o);set the outflow geometry type (to be done only once):
void outflow_set_params_circle(const Coords*, float3 c, float R, Outflow *o);
void outflow_set_params_plate(const Coords*, int dir, float r0, Outflow *o);this can be done via configuration file:
void outflow_set_conf(const Config *cfg, const Coords*, Outflow *);filter and mark particles (to be called at every time step):
void outflow_filter_particles(int n, const Particle *pp, /**/ Outflow *o); (1)
void outflow_download_ndead(Outflow *o); (2)
int* outflow_get_deathlist(Outflow *o); (3)
int outflow_get_ndead(Outflow *o); (4)| 1 | store dying particles infos inside Outflow struct |
| 2 | copy from device to host number of dead particles |
| 3 | return the list of dead marks (dead=1, alive=0) |
| 4 | return the number of dead particles |
10.3.2. configuration
plate
will delete particles crossing a plate along the positive direction.
syntax for the plate y=4:
outflow = {
active = true
type = "plate"
direction = 1 # [0,1,2] = [X,Y,Z]
position = 4.0 # position along "direction"
}circle
delete particles going out of the cylinder.
syntax for a cylinder of radius 8 centered at (8, 8, 8):
outflow = {
active = true
type = "circle"
R = 8.0
center = [8.0, 8.0, 8.0]
}10.4. den: Density controller
Delete particles in high density regions
10.4.1. interface
allocate, deallocate:
void den_ini(int maxp, /**/ DCont**);
void den_map_ini(DContMap**);
void den_fin(DCont*);
void den_map_fin(DContMap*);set the geometry type (to be done only once):
void den_map_set_none(const Coords*, DContMap*);
void den_map_set_circle(const Coords*, float R, DContMap*);this can be done via configuration file:
void den_map_set_conf(const Config*, const Coords*, DContMap*);filter and mark particles (to be called at every time step):
void outflow_filter_particles(int n, const Particle *pp, /**/ Outflow *o); (1)
void outflow_download_ndead(Outflow *o); (2)
int* outflow_get_deathlist(Outflow *o); (3)
int outflow_get_ndead(Outflow *o); (4)| 1 | reset the structure |
| 2 | internally mark particles in the regions with density higher than macdensity |
| 3 | internally download the number of dead particles |
The above functions only compute and store the results internally. The computed quantities can be accessed via:
void outflow_filter_particles(int n, const Particle *pp, /**/ Outflow *o); (1)
void outflow_download_ndead(Outflow *o); (2)
int* outflow_get_deathlist(Outflow *o); (3)
int outflow_get_ndead(Outflow *o); (4)| 1 | return a pointer to internal buffer with the "death list" |
| 2 | return the number of particles killed by the filter operation |
10.4.2. configuration
none
disabled density control everywhere
denoutflow = {
active = true
type = "none"
}circle
delete particles going out of a cylinder centered at the center of the domain. syntax for a cylinder of radius 8:
denoutflow = {
active = true
type = "circle"
R = 8.0
}11. coords
Coordinate transforms utility.
In uDeviceX, the simulation domain is decomposed into a grid of subdomains of equal sizes. Computations are performed in local coordinates and all objects are relative to these coordinates. Operations, such as initialisation of the data, io, etc., need global coordinates informations.
For convenience, we consider the three coordinate systems:
-
Global: Relative to the lower corner of the full domain of size \((G_x, G_y, G_z)\)
-
Local: Relative to the center of the subdomain of size \((L_x, L_y, L_z)\)
-
Center: Relative to the center of the full domain: \((C_x, C_y, C_z) = (G_x/2, G_y/2, G_z/2)\)
11.1. data structures
All the needed information is stored in the hidden structure Coords.
A view structure Coords_v is public to device code:
struct Coords_v {
int xc, yc, zc; /* rank coordinates */
int xd, yd, zd; /* rank sizes */
int Lx, Ly, Lz; /* [L]ocal: subdomain size */
};11.2. Host interface
11.2.1. Memory management
void coords_ini(MPI_Comm cart, int Lx, int Ly, int Lz, Coords **c); (1)
void coords_fin(Coords *c); (2)| 1 | allocate and set the data according to the cartesian communicator |
| 2 | deallocate the structure |
The resources can also be allocated using configuration informations:
void coords_ini_conf(MPI_Comm cart, const Config *cfg, Coords **c);11.2.2. Getters
Obtain a view structure from Coords:
void coords_get_view(const Coords *c, Coords_v *v);Get \((G_x, G_y, G_z)\):
int xdomain(const Coords *c);
int ydomain(const Coords *c);
int zdomain(const Coords *c);Get \((L_x, L_y, L_z)\):
int xs(const Coords*);
int ys(const Coords*);
int zs(const Coords*);
int3 subdomain(const Coords*);Get (from local coordinates) \((-L_x/2, -L_y/2, -L_z/2)\) and \((L_x/2, L_y/2, L_z/2)\) in global coordinates:
int xlo(const Coords*);
int ylo(const Coords*);
int zlo(const Coords*);
int xhi(const Coords*);
int yhi(const Coords*);
int zhi(const Coords*);11.2.3. Coordinate transforms
From local coordinates to center coordinates:
float xl2xc(const Coords *c, float xl);
float yl2yc(const Coords *c, float yl);
float zl2zc(const Coords *c, float zl);
void local2center(const Coords *c, float3 rl, /**/ float3 *rc);From center coordinates to local coordinates:
float xc2xl(const Coords *c, float xc);
float yc2yl(const Coords *c, float yc);
float zc2zl(const Coords *c, float zc);
void center2local(const Coords *c, float3 rc, /**/ float3 *rl);From local coordinates to global coordinates:
float xl2xg(const Coords *c, float xl);
float yl2yg(const Coords *c, float yl);
float zl2zg(const Coords *c, float zl);
void local2global(const Coords *c, float3 rl, /**/ float3 *rg);From global coordinates to local coordinates:
float xg2xl(const Coords *c, float xg);
float yg2yl(const Coords *c, float yg);
float zg2zl(const Coords *c, float zg);
void global2local(const Coords *c, float3 rg, /**/ float3 *rl);11.2.4. helpers
/* rank predicates */
bool is_end(const Coords *c, int dir);
/* a string unique for a rank */
void coord_stamp(const Coords *c, /**/ char *s);
/* number of subdomains */
int coords_size(const Coords *c);11.3. Configuration
Set subdomain sizes:
glb = {
L = [16, 12, 24]
}12. generic [d]evice API
The goal is to make cuda API and kernel functions generic. Meaning they can be replaced by CPU calls.
There are two groups: functions which "mirror" cuda API:
int GetSymbolAddress(void **devPtr, const void *symbol);
int Malloc(void **p, size_t);
int MemcpyToSymbol(const void *symbol, const void *src, size_t count, size_t offset=0, int kind=MemcpyHostToDevice);
int MemcpyFromSymbol(void *dst, const void *symbol, size_t count, size_t offset=0, int kind=MemcpyDeviceToHost);
int HostGetDevicePointer(void **pDevice, void *pHost, unsigned int flags);
int Memcpy (void *dst, const void *src, size_t count, int kind);
int MemsetAsync (void *devPtr, int value, size_t count, Stream_t stream=0);
int Memset (void *devPtr, int value, size_t count);
int MemcpyAsync (void * dst, const void * src, size_t count, int kind, Stream_t stream = 0);
int Free (void *devPtr);
int FreeHost (void *hstPtr);
int DeviceSynchronize (void);
int PeekAtLastError(void);functions unique for uDeviceX:
const char *emsg();
int alloc_pinned(void **pHost, size_t size);
int is_device_pointer(const void *ptr);files of the interface
- d/api.h API calls
- d/q.h function and variable type qualifiers
- d/ker.h
if DEV_CUDA is defined interfaces is implimented by cuda, if
DEV_CPU is defined it is implimented by host calls.
13. debug
Helper to check the particle positions, velocities, forces and cell-lists from device arrays
The hidden structure Dbg holds the debugging configuration.
Configuration is encoded using the following enum values:
enum {
DBG_POS, (1)
DBG_POS_SOFT, (2)
DBG_VEL, (3)
DBG_FORCES, (4)
DBG_COLORS, (5)
DBG_CLIST, (6)
DBG_NKIND_
};| 1 | positions are inside subdomain |
| 2 | positions are inside subdomain plus a margin |
| 3 | velocities |
| 4 | forces |
| 5 | colors |
| 6 | cell lists |
Consider subdomain of dimensions \((L_x, Ly, Lz)\). A position \((r_x, r_y, r_z)\) is valid if
where \(M\) is the margin. It is \(M = 0\) for DBG_POS and
\(M = 3\) for DBG_POS_SOFT.
For a given timestep \(dt\), the velocity \((v_x, v_y, v_z)\) is valid if
The force \((f_x, f_y, f_z)\) is valid if
13.1. interface
allocate/deallocate the structure:
void dbg_ini(Dbg**);
void dbg_fin(Dbg*);set debugging modes and verbosity:
void dbg_enable(int kind, Dbg *dbg);
void dbg_disable(int kind, Dbg *dbg);
void dbg_set_verbose(bool, Dbg *dbg);
void dbg_set_dump(bool, Dbg *dbg);initialize from configuration:
void dbg_set_conf(const Config*, Dbg*);interface:
void dbg_check_pos(const Coords *c, const char *base, const Dbg *dbg, int n, const Particle *pp);
void dbg_check_pos_soft(const Coords *c, const char *base, const Dbg *dbg, int n, const Particle *pp);
void dbg_check_vel(float dt, const Coords *c, const char *base, const Dbg *dbg, int n, const Particle *pp);
void dbg_check_forces(float dt, const Coords *c, const char *base, const Dbg *dbg, int n, const Particle *pp, const Force *ff);
void dbg_check_colors(const Coords *c, const Dbg *dbg, int n, const int *cc);
void dbg_check_clist(const Coords *c, const Dbg *dbg, int3 L, const int *starts, const int *counts, const Particle *pp);13.2. configuration
dbg = {
verbose = true;
pos = false;
pos_soft = false;
vel = false;
forces = false;
colors = false;
clist = false;
};14. distr
Redistribution of quantities across nodes.
Each node has a local coordinate system. The origin is the center of a
"subdomain" of size Sx, Sy, Sz.
A quantity is sent to a neighboring rank if its position is outside of the subdomain.
The workflow is very similar for every quantity to redistribute:
-
build a map from the positions of the quatities and store it in a
Mapstructure. -
pack the data using
Mapin aPackstructure -
communicaion: exchange packed data with neighbors, receive data into
Unpackstructure. This is done using the generic communicator. -
Unpack the data from
Unpackto quantities.
14.1. map
Helper for packing data to send buffers. This is common to all quantities.
14.1.1. data structure
The structure to map local data from an array to packed data in 27 arrays is implemented as:
/* [D]istr Map */
struct DMap {
int *counts; /* number of entities leaving in each fragment */
int *starts; /* cumulative sum of the above */
int *ids[27]; /* indices of leaving objects */
int *hcounts; /* counts on host (pinned) */
};This can be allocated on device or on host memory (see interface).
14.1.2. interface
Host interface:
void dmap_ini(int nfrags, const int capacity[], /**/ DMap *m);
void dmap_fin(int nfrags, /**/ DMap *m);
void dmap_reini(int nfrags, /**/ DMap m);
void dmap_download_counts(int nfrags, /**/ DMap *m);
void dmap_ini_host(int nfrags, const int capacity[], /**/ DMap *m);
void dmap_fin_host(int nfrags, /**/ DMap *m);
void dmap_reini_host(int nfrags, /**/ DMap m);
void dmap_D2H(int nfrags, const DMap *d, /**/ DMap *h);Device interface:
/* exclusive scan */
template <int NCOUNTS>
static __global__ void dmap_scan(/**/ DMap m) (1)
static __device__ int dmap_get_fid(int3 L, const float r[3]) (2)
static __device__ void dmap_add(int pid, int fid, DMap m) (3)| 1 | prefix sum on counts to obtain starts |
| 2 | get fragment id from position |
| 3 | add a quantity to the map |
14.2. flu
Redistribute solvent particles accross nodes.
14.2.1. data structures
Solvent distribution follow the common workflow described above and contains the three hidden generic data structures:
struct DFluPack {
DMap map;
dBags dbags[MAX_NBAGS], *dpp, *dii, *dcc;
hBags hbags[MAX_NBAGS], *hpp, *hii, *hcc;
int nbags;
int nhalo; /* number of sent particles */
int3 L; /* subdomain size */
CommBuffer *hbuf;
};
struct DFluComm {
Comm *comm;
};
struct DFluUnpack {
hBags hbags[MAX_NBAGS], *hpp, *hii, *hcc;
int nbags;
Particle *ppre;
int *iire, *ccre;
int nhalo; /* number of received particles */
int3 L; /* subdomain size */
CommBuffer *hbuf;
};where [d,h]xx means quantities on [device,host] and pp
corresponds to particles, cc to colors and ii to global ids.
The xxre variables in Unpack are buffer for remote quantities.
14.2.2. interface
void dflu_pack_ini(bool colors, bool ids, int3 L, int maxdensity, DFluPack **p);
void dflu_comm_ini(MPI_Comm comm, /**/ DFluComm **c);
void dflu_unpack_ini(bool colors, bool ids, int3 L, int maxdensity, DFluUnpack **u);
void dflu_pack_fin(DFluPack *p);
void dflu_comm_fin(DFluComm *c);
void dflu_unpack_fin(DFluUnpack *u);
/* map */
void dflu_build_map(int n, const PartList lp, DFluPack *p);
/* pack */
void dflu_pack(const FluQuants *q, /**/ DFluPack *p);
void dflu_download(DFluPack *p, /**/ DFluStatus *s);
/* communication */
void dflu_post_recv(DFluComm *c, DFluUnpack *u);
void dflu_post_send(DFluPack *p, DFluComm *c);
void dflu_wait_recv(DFluComm *c, DFluUnpack *u);
void dflu_wait_send(DFluComm *c);
/* unpack */
void dflu_unpack(/**/ DFluUnpack *u);The map is build from partlist, allowing the process to delete particles.
The solvent distribution also include cell list generation (see cell lists). It is done in two phases:
-
subindices, independant for bulk and remote particles
-
gather, which needs the subindices to be computed
Bulk subindices can be computed while comunicating remote particles.
/* cell lists */
void dflu_bulk(PartList lp, /**/ FluQuants *q);
void dflu_halo(const DFluUnpack *u, /**/ FluQuants *q);
void dflu_gather(int ndead, const DFluPack *p, const DFluUnpack *u, /**/ FluQuants *q);14.3. rbc
Redistribute red blood cells accross nodes according to the center of mass of their bounding box (see minmax).
14.3.1. data structures
RBC distribution follows the common workflow described above and contains the three hidden generic data structures:
enum {
MAX_NHBAGS = 2,
MAX_NDBAGS = 1
};
struct DRbcPack {
DMap map;
float3 *minext, *maxext;
dBags dbags[MAX_NDBAGS], *dpp;
hBags hbags[MAX_NHBAGS], *hpp, *hii;
int nbags;
CommBuffer *hbuf;
DMap hmap; /* host map for ids */
int3 L; /* subdomain size */
};
struct DRbcComm {
Comm *comm;
};
struct DRbcUnpack {
hBags hbags[MAX_NHBAGS], *hpp, *hii;
int nbags;
CommBuffer *hbuf;
int3 L; /* subdomain size */
};where minext and maxext contain the bounding box informations of
each RBC. Other variables have the same naming conventions than distr::flu.
14.3.2. interface
void drbc_pack_ini(bool ids, int3 L, int maxc, int nv, DRbcPack **p);
void drbc_comm_ini(MPI_Comm comm, /**/ DRbcComm **c);
void drbc_unpack_ini(bool ids, int3 L, int maxc, int nv, DRbcUnpack **u);
void drbc_pack_fin(DRbcPack *p);
void drbc_comm_fin(DRbcComm *c);
void drbc_unpack_fin(DRbcUnpack *u);
void drbc_build_map(int nc, int nv, const Particle *pp, DRbcPack *p);
void drbc_pack(const RbcQuants *q, /**/ DRbcPack *p);
void drbc_download(DRbcPack *p);
void drbc_post_recv(DRbcComm *c, DRbcUnpack *u);
void drbc_post_send(DRbcPack *p, DRbcComm *c);
void drbc_wait_recv(DRbcComm *c, DRbcUnpack *u);
void drbc_wait_send(DRbcComm *c);
void drbc_unpack_bulk(const DRbcPack *p, /**/ RbcQuants *q);
void drbc_unpack_halo(const DRbcUnpack *u, /**/ RbcQuants *q);Note that unpack_bulk can be done before unpacking halo quantities.
14.4. rig
Redistribute rigid objects accross nodes according to their center of mass.
14.4.1. data structures
Rigid bodies distribution is very similar to the above. The hidden data structures fit again in the general workflow:
/*
ipp: particles of the mesh
ss: "Rigid" structures
*/
enum {
ID_PP,
ID_SS,
MAX_NBAGS
};
struct DRigPack {
DMap map;
dBags dbags[MAX_NBAGS], *dipp, *dss;
hBags hbags[MAX_NBAGS], *hipp, *hss;
CommBuffer *hbuf;
int nbags;
int3 L; /* subdomain size */
};
struct DRigComm {
Comm *comm;
};
struct DRigUnpack {
hBags hbags[MAX_NBAGS], *hipp, *hss;
CommBuffer *hbuf;
int nbags;
int3 L; /* subdomain size */
};14.4.2. interface
void drig_pack_ini(int3 L, int maxns, int nv, DRigPack **p);
void drig_comm_ini(MPI_Comm comm, /**/ DRigComm **c);
void drig_unpack_ini(int3 L, int maxns, int nv, DRigUnpack **u);
void drig_pack_fin(DRigPack *p);
void drig_comm_fin(DRigComm *c);
void drig_unpack_fin(DRigUnpack *u);
void drig_build_map(int ns, const Rigid *ss, /**/ DRigPack *p);
void drig_pack(int ns, int nv, const Rigid *ss, const Particle *ipp, /**/ DRigPack *p);
void drig_download(DRigPack *p);
void drig_post_recv(DRigComm *c, DRigUnpack *u);
void drig_post_send(DRigPack *p, DRigComm *c);
void drig_wait_recv(DRigComm *c, DRigUnpack *u);
void drig_wait_send(DRigComm *c);
void drig_unpack_bulk(const DRigPack *p, /**/ RigQuants *q);
void drig_unpack_halo(const DRigUnpack *u, /**/ RigQuants *q);Note that unpack_bulk can be done before unpacking halo quantities.
14.5. common
helpers: common kernels
void dcommon_pack_pp_packets(int nc, int nv, const Particle *pp, DMap m, /**/ Sarray<Particle*, 27> buf); (1)
void dcommon_shift_one_frag(int3 L, int n, const int fid, /**/ Particle *pp); (2)
void dcommon_shift_halo(int3 L, int nhalo, const Sarray<int, 27> starts, /**/ Particle *pp); (3)| 1 | pack nc packets of nv particles into 27 buffers buf according to map |
| 2 | shift particles in the fragment direction |
| 3 | shift all particles according to the fragment direction |
15. exch
Exchange quantities across nodes for "ghost particles".
A quantity is exchanged with a neighboring node if its position is within a given distance from the subdomain boundaries.
The workflow is very similar for every quantity to exchange:
-
build a map from the positions of the quatities and store it in a
Mapstructure. -
pack the data using
Mapin aPackstructure -
communicaion: exchange packed data with neighbors, receive data into
Unpackstructure. This is done using the generic communicator. -
Unpack the data from
Unpackto quantities.
Optionally, other quantities can be exchanged back, e.g. forces.
15.1. map
Helper for packing data to send buffers. This is common to all quantities. As opposed to the distr module, the mapping is not one to one. A single quantity can be exchanged with up to 7 neighboring nodes if it is in a corner (exchange with 3 faces, 3 edges and one corner).
15.1.1. data structure
A single structure is able to build a map for up to nw objects
(e.g. rbc and rigid give nw = 2)
enum {MAX_FRAGS=26};
struct EMap {
int *counts; /* number of entities leaving in each fragment */
int *starts; /* cumulative sum of the above */
int *offsets; /* offsets per fragment for each solute */
int *ids[MAX_FRAGS]; /* indices of leaving objects */
int *cap; /* capacity of ids */
};for nw objects and nfrags fragments, the counts, starts and
offsets arrays all have the same size n = (nw + 1) * (nfrags + 1)
for convenience.
The nfrags + 1 part is for the starts, which is exclusive scan of
counts in the fragment dimension. Therefore the last element is the sum of counts, i.e. number
of entities for a given object.
The nw + 1 part is for offsets, which are an exclusive prefix sum of
counts in the object id dimension: the last row is the number of
entities of all objects leaving per fragment.
example: Given nw = 2 objects, with nfrags = 5 fragments, with the following
counts:
object 0: 0 2 2 1 4 object 1: 1 1 0 0 3 -> counts = 0 2 2 1 4 _ 1 1 0 0 3 _ _ _ _ _ _ _ -> starts = 0 0 2 4 5 9 0 1 1 1 1 4 _ _ _ _ _ _
where _ stands for "not set".
The offset array is then given by (we rewrite counts row by row for better understanding):
counts = 0 2 2 1 4 _
1 1 0 0 3 _
_ _ _ _ _ _
offsets = 0 0 0 0 0 _
0 2 2 1 4 _
1 3 2 1 7 _
starts and offsets are results of the scan operation (see below).
The index j used to retrieve the ith entity of a given object in a
given fragment is then given by
j = offsets[oid][fid] + starts[oid][fid] + i
where oid is the object id, fid the fragment.
note that above, [oid][fid] is implemented as [oid * (nfrags + 1) + fid].
The id is then ids[fid][j].
15.1.2. interface
Host interface:
void emap_ini(int nw, int nfrags, int cap[], /**/ EMap *map); (1)
void emap_fin(int nfrags, EMap *map); (2)
void emap_reini(int nw, int nfrags, /**/ EMap map); (3)
void emap_scan(int nw, int nfrags, /**/ EMap map); (4)
void emap_download_tot_counts(int nw, int nfrags, EMap map, /**/ int counts[]); (5)
void emap_download_all_counts(int nw, int nfrags, EMap map, /**/ int tot_counts[], int *counts[]);| 1 | allocate the map structure on device |
| 2 | deallocate the map structure |
| 3 | reset the map structure |
| 4 | scan the map structure to get starts and offsets |
| 5 | copy counts (total number of entities per fragment) from device to host |
Device interface:
_I_ int emap_code(int3 L, const float r[3]) (1)
_I_ int emap_code_box(int3 L, float3 lo, float3 hi) (2)
_I_ void emap_add(int nfrags, int soluteid, int pid, int fid, EMap m) (3)
_I_ int emap_decode(int code, /**/ int fids[MAX_DSTS]) (4)| 1 | get code (local fragment id) from position |
| 2 | get code (local fragment id) from box positions |
| 3 | add an entity id pid to the map in fragment fid and object soluteid. Does not add if the capacity is exceeded |
| 4 | get destination fragments from code |
15.2. flu
Exchange solvent particles within a cutoff radius from the neighboring nodes.
15.2.1. interface
allocate, deallocate the structures:
void eflu_pack_ini(bool colors, int3 L, int maxd, EFluPack **p);
void eflu_comm_ini(MPI_Comm comm, /**/ EFluComm **c);
void eflu_unpack_ini(bool colors, int3 L, int maxd, EFluUnpack **u);
void eflu_pack_fin(EFluPack *p);
void eflu_comm_fin(EFluComm *c);
void eflu_unpack_fin(EFluUnpack *u);build the map:
void eflu_compute_map(const int *start, const int *count, /**/ EFluPack *p);
void eflu_download_cell_starts(/**/ EFluPack *p);pack and copy data on host:
void eflu_pack(const PaArray *parray, /**/ EFluPack *p);
void eflu_download_data(EFluPack *p);communicate the packed data with neighbors:
void eflu_post_recv(EFluComm *c, EFluUnpack *u);
void eflu_post_send(EFluPack *p, EFluComm *c);
void eflu_wait_recv(EFluComm *c, EFluUnpack *u);
void eflu_wait_send(EFluComm *c);
void eflu_unpack(EFluUnpack *u);
using flu::LFrag26;
using flu::RFrag26;
void eflu_get_local_frags(const EFluPack *p, /**/ LFrag26 *lfrags);
void eflu_get_remote_frags(const EFluUnpack *u, /**/ RFrag26 *rfrags);unpack and get data informations needed by the fluforces module:
void eflu_unpack(EFluUnpack *u);
using flu::LFrag26;
using flu::RFrag26;
void eflu_get_local_frags(const EFluPack *p, /**/ LFrag26 *lfrags);
void eflu_get_remote_frags(const EFluUnpack *u, /**/ RFrag26 *rfrags);15.3. obj
Object exchanger is used to exchange particles from objects (rbc or rig) with neighboring nodes for computing their interactions with the solvent (fsi) or with other objects (contact forces). It sends the remote forces back to the local node.
Sending back the forces is optional.
15.3.1. particle exchange interface
allocate, deallocate the structures:
void eobj_pack_ini(int3 L, int nw, int maxd, int maxpsolid, EObjPack **p);
void eobj_comm_ini(MPI_Comm cart, /**/ EObjComm **c);
void eobj_unpack_ini(int3 L, int nw, int maxd, int maxpsolid, EObjUnpack **u);
void eobj_pack_fin(EObjPack *p);
void eobj_comm_fin(EObjComm *c);
void eobj_unpack_fin(EObjUnpack *u);build the map from array of wrappers PaWrap containing array of particles:
void eobj_build_map(int nw, const PaWrap *ww, /**/ EObjPack *p);pack the data:
void eobj_pack(int nw, const PaWrap *ww, /**/ EObjPack *p);
void eobj_download(int nw, EObjPack *p);communicate the packed data with neighboring nodes:
void eobj_post_recv(EObjComm *c, EObjUnpack *u);
void eobj_post_send(EObjPack *p, EObjComm *c);
void eobj_wait_recv(EObjComm *c, EObjUnpack *u);
void eobj_wait_send(EObjComm *c);retrieve information about the received data:
int26 eobj_get_counts(EObjUnpack *u); (1)
void eobj_get_all_counts(int nw, EObjUnpack *u, int *all_counts);
Pap26 eobj_upload_shift(EObjUnpack *u); (2)
Fop26 eobj_reini_ff(const EObjUnpack *u, EObjPackF *pf); (3)| 1 | get the number of particles inside each fragment |
| 2 | upload particles on device, shift them in local coordinates and return device pointers |
| 3 | set forces on device to 0 and return device pointers |
15.3.2. force back sender interface
allocate, deallocate the optional structures:
void eobj_packf_ini(int3 L, int maxd, int maxpsolid, EObjPackF **p);
void eobj_commf_ini(MPI_Comm cart, /**/ EObjCommF **c);
void eobj_unpackf_ini(int3 L, int maxd, int maxpsolid, EObjUnpackF **u);
void eobj_packf_fin(EObjPackF *p);
void eobj_commf_fin(EObjCommF *c);
void eobj_unpackf_fin(EObjUnpackF *u);download the forces on host:
void eobj_download_ff(EObjPackF *p);communicate back the forces to neighbours:
void eobj_post_recv_ff(EObjCommF *c, EObjUnpackF *u);
void eobj_post_send_ff(EObjPackF *p, EObjCommF *c);
void eobj_wait_recv_ff(EObjCommF *c, EObjUnpackF *u);
void eobj_wait_send_ff(EObjCommF *c);unpack forces arrays inside wrappers FoWrap.
void eobj_unpack_ff(EObjUnpackF *u, const EObjPack *p, int nw, /**/ FoWrap *ww);15.4. mesh
exchange full mesh particles with neighbouring nodes when bounding box of the mesh crosses or is close enough to the subdomain boundaries. This is used for mesh bounce back or solvent recoloring.
It can optionally send back momentum data per triangles to original node.
15.4.1. mesh exchanger interface
allocate, deallocate:
void emesh_pack_ini(int3 L, int nv, int max_mesh_num, EMeshPack **p);
void emesh_comm_ini(MPI_Comm comm, /**/ EMeshComm **c);
void emesh_unpack_ini(int3 L, int nv, int max_mesh_num, EMeshUnpack **u);
void emesh_pack_fin(EMeshPack *p);
void emesh_comm_fin(EMeshComm *c);
void emesh_unpack_fin(EMeshUnpack *u);build map:
void emesh_build_map(int nm, int nv, const Particle *pp, /**/ EMeshPack *p);pack data:
void emesh_pack_pp(int nv, const Particle *pp, /**/ EMeshPack *p);
void emesh_pack_rrcp(int nv, const Positioncp *rr, /**/ EMeshPack *p);
void emesh_download(EMeshPack *p);communicate data with neigbours:
void emesh_post_recv(EMeshComm *c, EMeshUnpack *u);
void emesh_post_send(EMeshPack *p, EMeshComm *c);
void emesh_wait_recv(EMeshComm *c, EMeshUnpack *u);
void emesh_wait_send(EMeshComm *c);unpack the data to a single particle array:
void emesh_unpack_pp(int nv, const EMeshUnpack *u, /**/ int *nmhalo, Particle *pp);
void emesh_unpack_rrcp(int nv, const EMeshUnpack *u, /**/ int *nmhalo, Positioncp *rr);the returned value nmhalo is the number of
received meshes
get number of mesh per fragment:
void emesh_get_num_frag_mesh(const EMeshUnpack *u, /**/ int cc[NFRAGS]);15.4.2. back momentum sender interface
allocate, deallocate the optional structures:
void emesh_packm_ini(int num_mom_per_mesh, int max_mesh_num, EMeshPackM **p);
void emesh_commm_ini(MPI_Comm comm, /**/ EMeshCommM **c);
void emesh_unpackm_ini(int num_mom_per_mesh, int max_mesh_num, EMeshUnpackM **u);
void emesh_packm_fin(EMeshPackM *p);
void emesh_commm_fin(EMeshCommM *c);
void emesh_unpackm_fin(EMeshUnpackM *u);pack the momentum infos
void emesh_packM(int nt, const int counts[NFRAGS], const Momentum *mm, /**/ EMeshPackM *p);
void emesh_downloadM(const int counts[NFRAGS], EMeshPackM *p);communicate back the momentum infos:
void emesh_post_recv(EMeshCommM *c, EMeshUnpackM *u);
void emesh_post_send(EMeshPackM *p, EMeshCommM *c);
void emesh_wait_recv(EMeshCommM *c, EMeshUnpackM *u);
void emesh_wait_send(EMeshCommM *c);unpack the momentum infos to a single array:
void emesh_upload(EMeshUnpackM *u);
void emesh_unpack_mom(int nt, const EMeshPack *p, const EMeshUnpackM *u, /**/ Momentum *mm);15.5. common
helper for common exchange operations
void ecommon_pack_pp(const Particle *pp, PackHelper ph, /**/ Pap26 buf); (1)
void ecommon_shift_pp_one_frag(int3 L, int n, const int fid, /**/ Particle *pp); (2)
void ecommon_shift_rrcp_one_frag(int3 L, int n, const int fid, /**/ Positioncp *rr);| 1 | pack particles pp into 27 buffers buf according to the local map ph |
| 2 | shift particles in the fragment direction |
The local map is defined through the structure
struct PackHelper {
int *starts;
int *offsets;
int *indices[NFRAGS];
int *cap;
};which is a map for a single set of quantities.
16. flu: solvent particles
Manages solvent particles data.
16.1. data structure
The data is stored in a visible structure. The user can access directly the fields.
struct FluQuants {
Particle *pp, *pp0; /* particles on device */
int n; /* particle number */
Clist *cells; /* cell lists */
ClistMap *mcells; /* cell lists map */
Particle *pp_hst; /* particles on host */
/* optional data */
bool ids, colors;
int *ii, *ii0; /* global ids on device */
int *ii_hst; /* global ids on host */
int *cc, *cc0; /* colors on device */
int *cc_hst; /* colors on host */
int maxp; /* maximum particle number */
};16.2. interface
allocate and deallocate the data:
void flu_ini(bool colors, bool ids, int3 L, int maxp, FluQuants *q);
void flu_fin(FluQuants *q);generate the quantities:
void flu_gen_quants(const Coords*, int numdensity, const GenColor *gc, FluQuants *q); (1)
void flu_gen_ids(MPI_Comm, const int n, FluQuants *q); (2)| 1 | generate numberdensity particles randomly distributed in every
cell with zero velocity. Colors are optionally set from GenColor
object (see color). |
| 2 | generate unique global ids for each particle |
restart interface (see restart):
void flu_strt_quants(MPI_Comm, const char *base, const int id, FluQuants *q); (1)
void flu_strt_dump(MPI_Comm, const char *base, const int id, const FluQuants *q); (2)| 1 | read quantities from restart files |
| 2 | dump quantities to restart files |
additional tools:
void flu_txt_dump(const Coords*, const FluQuants *q); (1)
/* build cells only from one array of particles fully contained in the domain */
/* warning: this will delete particles which are outside */
void flu_build_cells(/**/ FluQuants *q); (2)| 1 | dump particles to text format, one file per MPI rank (debug purpose) |
| 2 | build cells lists, assume that particles are inside subdomain |
17. fluforces
solvent forces
17.1. interface
allocate and free bulk structure:
void fluforces_bulk_ini(int3 L, int maxp, /**/ FluForcesBulk **b);
void fluforces_bulk_fin(/**/ FluForcesBulk *b);compute bulk interactions:
void fluforces_bulk_prepare(int n, const PaArray *a, /**/ FluForcesBulk *b);
void fluforces_bulk_apply(const PairParams*, int n, const FluForcesBulk *b, const int *start, const int *count,
/**/ const FoArray *ff);allocate and free halo structure:
void fluforces_halo_ini(MPI_Comm cart, int3 L, /**/ FluForcesHalo **hd);
void fluforces_halo_fin(/**/ FluForcesHalo *h);compute halo interactions:
void fluforces_halo_prepare(flu::LFrag26 lfrags, flu::RFrag26 rfrags, /**/ FluForcesHalo *h);
void fluforces_halo_apply(const PairParams*, const FluForcesHalo *h, /**/ const FoArray *farray);17.2. submodules
17.2.1. bulk
compute local interactions of solvent particles, given cell starts, cell counts (see clist) and particles array
The algorithm is as follows:
-
each particle of the array has one thread assigned.
-
the thread runs over half of the 27 cell lists overlapping one cutoff radius (this makes 13 cells + the "self cell")
-
in each cell, the particle ids are fetched from the cell starts array
-
run over particles, atomic add the forces to them and gather forces on the main particle
-
atomic add main forces to force array
Performance is strongly related to the pattern used to run over the
particles.
Better performance is achieved by grouping as much as possible
consecutive particles (row), meaning that the x cell index runs
fastest.
The cell run order is shown below:
+----> x plane dz = -1: plane dz = 0: plane dz = +1:
|
| 00 01 02 09 10 11 xx xx xx
v y 03 04 05 12 13 xx xx xx xx
06 07 08 xx xx xx xx xx xx
where xx denotes that the cell is not used by the current thread.
17.2.2. halo
solvent forces with remote particles (fragments)
main kernel performs interactions for a given halo:
-
fetch generalized particle
a -
build map (how to access neighboring particles?)
-
loop over neighboring particles according to map
-
compute pairwise interactions
-
accumulate to force
ain output force array
18. frag
Fragment functions on host and device
18.1. purpose
A fragment designates one of the 27 directions \((dx, dy, dz)\), where \(dx, dy, dz \in \{-1, 0, 1\}\).
The fragment \((0, 0, 0)\) is called bulk and has the id frag_bulk.
The purpose of this module is to encode and decode the fragments between fragment ids (numbered from 0 to 26) and directions.
18.2. interface
The major part of the functions are available to both device and host,
within the namespaces fragdev and fraghst, respectively.
int i2dx(int i); (1)
int i2dy(int i); (2)
int i2dz(int i); (3)
void i2d3(int i, /**/ int d[3]); (4)| 1 | get \(dx\) from fragment id |
| 2 | get \(dy\) from fragment id |
| 3 | get \(dz\) from fragment id |
| 4 | get \((dx, dy, dz)\) from fragment id |
int d2i(int x, int y, int z); (1)
int d32i(const int d[3]); (2)| 1 | get fragment id from \((dx, dy, dz)\) |
| 2 | idem with array as input |
int ncell(int3 L, int i); (1)| 1 | given sub-domain sizes L, returns number of neighboring cells to
fragment with id i |
int antid2i(int x, int y, int z); (1)
int anti(int i); (2)| 1 | given \((dx, dy, dz)\), return the id of the anti fragment (i.e. with direction \((-dx, -dy, -dz)\)) |
| 2 | given a fragment id, returns the id of the anti fragment |
Only on host:
void estimates(int3 L, int nfrags, float maxd, /**/ int *cap); (1)| 1 | given a maximum number density maxp, return an estimate of the
number of particles in each fragment layer. |
19. fsi : flow structure interactions
flow-structure interactions between solvent and objects (rigid objects, rbc membranes)
19.1. interface
allocate/deallocate
void fsi_ini(int rank, int3 L, /**/ Fsi **fsi);
void fsi_fin(Fsi *fsi);computing forces:
void fsi_bind_solvent(PaArray pa, Force *ff, int n, const int *starts, /**/ Fsi *fsi); (1)
void fsi_bulk(Fsi *fsi, int nw, const PairParams **prms, PaWrap *pw, FoWrap *fw); (2)
void fsi_halo(Fsi *fsi, int nw, const PairParams **prms, Pap26 all_pp, Fop26 all_ff, const int *all_counts); (3)| 1 | store solvent interactions inside hidden structure Fsi |
| 2 | compute the interactions between local objects and local solvent |
| 3 | compute the interactions between remote objects and local solvent |
20. grid_sampler: particle to grid average
gather particle data on a grid and average in time. The particle to grid process is simple binning.
20.1. quantities
The number density and velocity (3 components) are computed by default. Optionally, the stress tensor (6 components) and the color proportions can be sampled as well.
All cell quantities computed at a given time \(t\) are averaged on time:
The cell quantities \(Q^i_t\) are averaged on space, depending on the quantity. Let \(j \in [1, n_i\)] denote the particle ids inside cell \(i\), where \(n_i\) is the number of particles inside this cell. \(V_i\) denotes the volume of the cell.
Velocity:
number density:
stress:
color proportion:
20.2. interface
Allocate and free the structure:
void grid_sampler_ini(bool colors, bool stress, int3 L, int3 N, GridSampler**); (1)
void grid_sampler_fin(GridSampler*); (2)| 1 | create a sampler for binning a subdomain of size L. N is the
number of bins. Allocate space for stress when stress is set to
true. Allocate space for the color proportions when colors is
set to true. |
| 2 | deallocate the structure |
The sampler object stores the grid data. All operations are performed on device:
void grid_sampler_reset(GridSampler*); (1)
void grid_sampler_add(const GridSampleData*, GridSampler*); (2)
void grid_sampler_dump(MPI_Comm, const char *dir, long id, GridSampler*); (3)| 1 | set all fields of the grids to 0 |
| 2 | add contribution of the data (see grid sampler data) to the time averaged grid |
| 3 | perform time average of all gathered data, download grid on host and dump to file (see grid). |
20.3. grid sampler data
helper to pass data to the grid sampler.
allocate and deallocate the data structure:
void grid_sampler_data_ini(GridSampleData **);
void grid_sampler_data_fin(GridSampleData *);pass data to the structure:
void grid_sampler_data_reset(GridSampleData *); (1)
void grid_sampler_data_push(long n, const Particle *pp, const int *cc,
const float *ss, GridSampleData *); (2)| 1 | remove all previously pushed data |
| 2 | add data (pointers only, not a deep copy) to the structure. The
pp pointer is mandatory. The stress ss pointer is used only when
stress is activated in grid sampler. The colors cc pointer is
only used when colors is activated in the grid sampler. |
21. IO
21.1. grid
Parallel-IO grid data dump using the hdf5 library and a xmf file description.
21.1.1. interface
The following function dumps grid data with subGrid points per node
mapped to the subdomain coordinates of size subDomain.
Two files DUMP_BASE/dir/id.xmf and DUMP_BASE/dir/id.h5 are dumped.
void grid_write(int3 subGrid, int3 subDomain, MPI_Comm, const char *path, int ncmp, const float **data, const char **names);-
ncmp: number of variables -
data: data to dump (structure of array fashion) -
names: variable names
21.1.2. submodules
xmf writer, to be called by one rank only:
void xmf_write(int3 domainSize, int3 gridSize, const char *path, int ncomp, const char **names);h5 writer, collective write operation:
void h5_write(int3 N, MPI_Comm, const char *path, int ncomp, const float **data, const char **names);N is the grid size.
21.2. Low level MPI file write
int write_file_open(MPI_Comm, const char *path, /**/ WriteFile**);
int write_file_close(WriteFile*);
void write_all(MPI_Comm, const void *const, int nbytes, WriteFile*); (1)
int write_master(MPI_Comm, const void *const, int nbytes, WriteFile*); (2)
int write_shift_indices(MPI_Comm, int, /**/ int*);
int write_reduce(MPI_Comm, int, /**/ int*);| 1 | write nbytes from every prcesses |
| 2 | write nbytes onlye from master process (rank = 0) |
21.3. Text
Write one row per particle in a text file path.
void txt_write_pp(long n, const Particle*, const char *path);
void txt_write_pp_ff(long n, const Particle*, const Force*, const char *path);Read particles to a structure TxtRead. The TxtRead API returns the
number of particles and pointers to the data. txt_read_fin frees the
memory and invalidated pointers returned by txt_read_get_pp or
txt_read_get_pp_ff.
void txt_read_pp(const char *path, TxtRead **);
void txt_read_pp_ff(const char *path, TxtRead **);
void txt_read_ff(const char *path, TxtRead **);
void txt_read_fin(TxtRead*);
int txt_read_get_n(const TxtRead *);
const Particle* txt_read_get_pp(const TxtRead *);
const Force* txt_read_get_ff(const TxtRead *);Text format is a as follow:
x y z vx vy vz [fx fy fz] ... x y z vx vy vz [fx fy fz]
where every row corresponds to a particle.
21.4. Mesh
x0 y0 z0 x1 y1 z1 ... x[nv-1] y[nv-1] z[nv-1]
Triangles are packed in array of int4 with fields w left
unused. For example, traingle i is
tt[i].x tt[i].y tt[i].z
mesh_get_nt, mesh_get_nv, mesh_get_ne, and mesh_get_md return
the number of triangles, number of vertices, number of edges, and
maximum degree.
void mesh_read_ini_off(const char *path, MeshRead**);
void mesh_read_ini_ply(const char *path, MeshRead**);
void mesh_read_fin(MeshRead*);
int mesh_read_get_nt(const MeshRead*);
int mesh_read_get_nv(const MeshRead*);
int mesh_read_get_ne(const MeshRead*);
int mesh_read_get_md(const MeshRead*);
const int4 *mesh_read_get_tri(const MeshRead*);
const float *mesh_read_get_vert(const MeshRead*);
const int4 *mesh_read_get_dih(MeshRead*);21.5. Diagnostics
21.5.1. Particle
Uses only particles values. Dumps output to log files and to file
path.
void diag_part_ini(const char *path, /**/ DiagPart**);
void diag_part_fin(DiagPart*);
void diag_part_apply(DiagPart*, MPI_Comm, float time, int n, const Particle*);21.5.2. Mesh
Uses particle values and mesh.
21.6. Point
Write point data to bop files.
A configuration structure
void io_point_conf_ini(/**/ IOPointConf**);
void io_point_conf_fin(IOPointConf*);
void io_point_conf_push(IOPointConf*, const char *keys);Push data
void io_point_ini(int maxn, const char *path, IOPointConf*, /**/ IOPoint**);
void io_point_fin(IOPoint*);
void io_point_push(IOPoint*, int n, const double *data, const char *keys);
void io_point_write(IOPoint*, MPI_Comm comm, int id);Example
enum {X, Y, Z};
int i, id;
double *r, rr[3*MAX_N], density[MAX_N];
IOPointConf *c;
IOPoint *p;
for (i = 0; i < MAX_N; i++) {
r = &rr[3*i];
r[X] = i; r[Y] = 10*i; r[Z] = 100*i;
density[i] = -i;
}
UC(io_point_conf_ini(&c));
UC(io_point_conf_push(c, "x y z"));
UC(io_point_conf_push(c, "density"));
UC(io_point_ini(MAX_N, path, c, &p));
UC(io_point_conf_fin(c));
UC(io_point_push(p, MAX_N, rr, "x y z"));
UC(io_point_push(p, MAX_N, density, "density"));
id = 0;
UC(io_point_write(p, comm, id));21.7. VTK
Write vertices and triangles data to legacy vtk files. VTK structure
uses VTKConf structure for initialization.
A configuration structure.
void vtk_conf_ini(MeshRead*, /**/ VTKConf**); (1)
void vtk_conf_fin(VTKConf*);
void vtk_conf_vert(VTKConf*, const char *keys); (2)
void vtk_conf_tri(VTKConf*, const char *keys); (3)| 1 | initilize configuration structure |
| 2 | "register" a "key" for data on vertices |
| 3 | "register" a "key" for data on triangles |
Push data
void vtk_ini(MPI_Comm, int maxm, char const *dir, VTKConf*, /**/ VTK**); (1)
void vtk_points(VTK*, int nm, const Vectors*); (2)
void vtk_vert(VTK*, int nm, const Scalars*, const char *keys); (3)
void vtk_tri(VTK*, int nm, const Scalars*, const char *keys); (4)
void vtk_write(VTK*, MPI_Comm, int id); (5)
void vtk_fin(VTK*);| 1 | initilize the structure, create directory |
| 2 | "push" coordinates of the vertices |
| 3 | "push" vertices data |
| 4 | "push" triangle data |
| 5 | write a file |
21.8. restart
Dump and read restart files to restart simulation at a given time. Uses the bop file format.
21.8.1. naming
The restart files are named as:
BASE/CODE/ID.bop BASE/CODE/ID.values
-
BASE: can be different for dump and read. Set to "strt" indefault.cfg. -
CODE: specified by the user, seecodeparameter in the interface. By convention, it corresponds to the quantity name followed by an additional specifier, such as "flu.pp" for particles of the solvent. -
ID: a string specific to the time step. Common value is the dump index starting from 0. Special values are described in interface
21.8.2. interface
Writing a single file for all ranks:
void restart_write_pp(MPI_Comm, const char *base, const char *code, int id, long n, const Particle *pp); (1)
void restart_write_ii(MPI_Comm, const char *base, const char *code, int id, long n, const int *ii); (2)
void restart_write_ss(MPI_Comm, const char *base, const char *code, int id, long n, const Rigid *ss); (3)
void restart_write_stream_one_node(MPI_Comm, const char *base, const char *code, int id, const void *data, StreamWriter); (4)| 1 | write particle data |
| 2 | write integer data |
| 3 | write rigid data |
| 4 | the master rank only writes to a stream (text file) |
The stream writer and reader make use of a function pointer:
typedef void (*StreamWriter)(const void*, FILE*);
typedef void (*StreamReader)(FILE*, void*);where the data is passed through a void pointer.
The reader functions are symmetric to the writer:
void restart_read_pp(MPI_Comm, const char *base, const char *code, int id, int *n, Particle *pp);
void restart_read_ii(MPI_Comm, const char *base, const char *code, int id, int *n, int *ii);
void restart_read_ss(MPI_Comm, const char *base, const char *code, int id, int *n, Rigid *ss);
void restart_read_stream_one_node(const char *base, const char *code, int id, StreamReader, void *data);The parameters are:
-
a communicator of all ranks dumping or reading the file
-
base: a string representing the base directory name -
code: a string containing the directory name -
id: the index of dump (starting at 0). Special values can be passed:
enum {RESTART_TEMPL=-1,
RESTART_FINAL=-2};
enum {RESTART_BEGIN=RESTART_FINAL};The final and begin special ids will replace the id part with the string
"final". It is used to dump the last restart file.
The templ special id will replace the id part with the string
"templ". It is used for special quantities which do not change during
the whole simulation, such as wall frozen particles or rigid frozen particles.
22. inter: interprocessing tools
Interprocessing tools: not pre or post processing, happens inside simulation…
-
generate initial solvent colors
22.1. color
Generate colors initial conditions
22.1.1. interface
allocate, deallocate the helper structure:
void inter_color_ini(GenColor**);
void inter_color_fin(GenColor*);set the geometry type
void inter_color_set_drop(float R, GenColor*); (1)
void inter_color_set_uniform(GenColor*); (2)| 1 | color with RED a ball of radius R in the center of the domain,
and the rest BLUE |
| 2 | color all particles as BLUE |
this can also be set via configuration file:
void inter_color_set_conf(const Config*, GenColor*);Apply coloring to a set of particles host or device arrays:
void inter_color_apply_hst(const Coords*, const GenColor*, int n, const Particle *pp, /**/ int *cc);
void inter_color_apply_dev(const Coords*, const GenColor*, int n, const Particle *pp, /**/ int *cc);23. Math
Helpers for math operations and random number generation
23.1. linal
Linear algebra functions
void linal_inv3x3(const float m0[6], /**/ float minv0[6]); (1)| 1 | inverse symmetric 3 by 3 matrix; fails for singular matrices with
determinant smaller than epsilon (hardcoded to 1e-8). |
structure of the matrix is xx, xy, yy, yz, zz, where
23.2. Host random number generation
Generate uniform random numbers on host in floating point precision. Uses KISS algorithm
struct RNDunif; (1)
void rnd_ini(int x, int y, int z, int c, /**/ RNDunif **r); (2)
void rnd_fin(RNDunif *r); (3)
float rnd_get(RNDunif *r); (4)| 1 | hidden structure containing state of the rng |
| 2 | allocate and initialize the rng (x, y, z and c are states of the rng) |
| 3 | deallocate rng states |
| 4 | generate a random number in single precision; modify the state |
23.3. tform: linar coordinate transformation for 3D vector
Transform vector a[3] to b[3] using
b[X] = s[X]*a[X] + o[X]
b[Y] = s[Y]*a[Y] + o[Y]
b[Z] = s[Z]*a[Z] + o[Z]
Coefficient s and o are defined implicitly by API calls.
23.3.1. interface
Allocate/Deallocate
void tform_ini(Tform**);
void tform_fin(Tform*);Set parameters of the transformation, some transfroms are for grids which are cell centered and defined by low and high boundaries and the number of cell.
void tform_vector(const float a0[3], const float a1[3], const float b0[3], const float b1[3], /**/ Tform*); (1)
void tform_chain(const Tform *A, const Tform *B, /**/ Tform *C); (2)
void tform_to_grid(const float lo[3], const float hi[3], const int n[3], /**/ Tform*); (3)
void tform_from_grid(const float a0[3], const float b0[3], const int n[3], /**/ Tform*); (4)
void tform_grid2grid(const float f_lo[3], const float f_hi[3], const int f_n[3],
const float t_lo[3], const float t_hi[3], const int t_n[3],
Tform*); (5)| 1 | converts vectors a0 to a1 and b0 to b1 |
| 2 | a chain of two transforms: C(x) is equivalent to 'B(A(x))' |
| 3 | transfrom to a grid: for example, it transfroms lo to -1/2 and hi to n - 1/2 |
| 4 | transfrom from a grid: for example, it transfroms -1/2 to lo and n - 1/2 to hi |
| 5 | grid to grid transform |
Convert vector
void tform_convert(const Tform*, const float a0[3], /**/ float a1[3]);convert to view
void tform_to_view(const Tform*, /**/ Tform_v*);log
Log or dump the state of 'Tform'
void tform_log(Tform*);
void tform_dump(Tform*, FILE*);23.4. triangle functions
Host and device functions for a given triangle. For area computation a formula stable to numerical error is used.
double kahan_area0(double a, double b, double c); (1)
double kahan_area(const double a[3], const double b[3], const double c[3]); (2)
void ac_bc_cross(const double a[3], const double b[3], const double c[3], /**/ double r[3]); (3)
double shewchuk_area(const double a[3], const double b[3], const double c[3]); (4)
double orient3d(const double a[3], const double b[3], const double c[3], const double d[3]); (5)
void dihedral_xy(const double a[3], const double b[3], const double c[3], const double d[3],
double *x, double *y); (6)| 1 | area of a triangle given sides |
| 2 | area of a triangle given coordinate of the vertices |
| 3 | \( \left(\mathbf{a} - \mathbf{c}\right) \times \left(\mathbf{b} - \mathbf{c}\right)\) |
| 4 | area of a triangle given coordinate of the vertices using "Shewchuk formula" |
| 5 | orient3d from Jonathan Richard Shewchuk |
| 6 | dihedral angle |
24. Mesh
helpers for computation on triangle mesh.
Mesh are stored with an array of vertices (vv) or particles (pp) in an array of
structure fashion.
The connectivity is a set of vertices indices grouped by triangles.
For performance and convenience reasons, they are stored in a int4
array, each element storing ids of the three vertices of the triangle
(the last field is not used).
24.1. area: compute area of a mesh
Compute the area of a triangulated mesh.
void mesh_area_ini(MeshRead*, /**/ MeshArea**); (1)
void mesh_area_fin(MeshArea*);
double mesh_area_apply0(MeshArea*, Vectors*); (2)
void mesh_area_apply(MeshArea*, int nm, Vectors*, /**/ double*); (3)| 1 | in initialization triangles are stored |
| 2 | compute the area of one object |
| 3 | compute the areas of nm objects |
24.2. tri_area: compute area of triangles in a mesh
Compute the area of every triangle of the mesh.
void mesh_tri_area_ini(MeshRead*, /**/ MeshTriArea**); (1)
void mesh_tri_area_fin(MeshTriArea*);
void mesh_tri_area_apply(MeshTriArea*, int nm, Vectors*, /**/ double*); (2)| 1 | in initialization triangles are stored |
| 2 | compute areas |
nm is the number of meshes.
24.3. angle: compute angles between triangles with a common edge
void mesh_angle_ini(MeshRead*, /**/ MeshAngle**); (1)
void mesh_angle_fin(MeshAngle*);
void mesh_angle_apply(MeshAngle*, int nm, Vectors*, /**/ double*); (2)| 1 | in initialization triangles are stored |
| 2 | triangle for nm objects, the size of the output is nm * ne |
24.4. edges length: compute length of the edges
void mesh_edg_len_ini(MeshRead*, MeshEdgLen**); (1)
void mesh_edg_len_fin(MeshEdgLen*);
void mesh_edg_len_apply(MeshEdgLen*, int nm, Vectors*, /**/ double*); (2)| 1 | in initialization triangles are stored |
| 2 | edges for nm objects, the size of the output is nm * ne |
24.5. gen: generate mesh
Generate mesh vertices from template mesh and affine transform matrices (see matrices submodule).
/* vv : vertices of the mesh template : x y z x y z, ... */
int mesh_gen_from_file(const Coords*, const float *vv, const char *ic, int nv, /**/ Particle*); (1)
void mesh_gen_from_matrices(int nv, const float *vv, const Matrices*, /**/ int *pn, Particle*); (2)
void mesh_shift(const Coords*, int n, /**/ Particle*); (3)| 1 | generate and filter meshes from file ic. Only those
belonging to subdomain are kept. |
| 2 | generate from a matrices array |
| 3 | shift a set of vertices particles from global to local coordinates |
24.6. matrices: affine transformation
An array of 4 x 4 affine transformation matrices.
void matrices_read(const char *path, /**/ Matrices**); (1)
void matrices_read_filter(const char *path, const Coords*, /**/ Matrices**); (2)
void matrices_get(const Matrices*, int i, /**/ double**); (3)
void matrices_get_r(const Matrices*, int i, /**/ double r[3]); (4)
int matrices_get_n(const Matrices*); (5)
void matrices_log(const Matrices*); (6)
void matrices_fin(Matrices*);| 1 | read from input file |
| 2 | read from input file and keep only matrices which "belong" to this MPI rank |
| 3 | return matrix as double[16] |
| 4 | return the shift of the ith matrix as double[3] |
| 5 | return the number of matrices |
| 6 | print the array of matrices to stderr using msg_print |
24.7. "scatter": distribute scalar values between different elements of the mesh
void mesh_scatter_ini(MeshRead*, MeshScatter**); (1)
void mesh_scatter_fin(MeshScatter*);
void mesh_scatter_edg2vert(MeshScatter*, int nm, Scalars*, /**/ double*); (2)
void mesh_scatter_edg2vert_avg(MeshScatter*, int nm, Scalars*, /**/ double*); (2)| 1 | in initialization triangles are stored |
| 2 | edge to vertices |
24.8. Triangles
Triangles on device. It is created from MeshRead*.
void triangles_ini(MeshRead*, /**/ Triangles**);
void triangles_fin(Triangles*);the client must include type.h and can access fields directly.
struct Triangles {
int4 *tt;
int nt;
};nt is the number of triangles.
24.9. vertices' area
Compute area associated with every vertices. Assume every adjusting triangle contributes one third it its area to a vertice.
void mesh_vert_area_ini(MeshRead*, /**/ MeshVertArea**); (1)
void mesh_vert_area_fin(MeshVertArea*);
void mesh_vert_area_apply(MeshVertArea*, int nm, Vectors*, /**/ double*); (2)| 1 | in initialization triangles are stored |
| 2 | compute area |
24.10. volume: compute volume of a mesh
Compute the volume enclosed by a triangulated mesh on host.
void mesh_volume_ini(MeshRead*, /**/ MeshVolume**); (1)
void mesh_volume_fin(MeshVolume*);
double mesh_volume_apply0(MeshVolume*, Vectors*); (2)
void mesh_volume_apply(MeshVolume*, int nm, Vectors*, /**/ double*); (3)| 1 | in initialization triangles are stored |
| 2 | compute volume for one object |
| 3 | compute volume for nm objects |
25. pair: pairwise interactions
pairwise forces. manages the parameters for dpd and repulsive Lennard-Jones parameters.
25.1. dpd interactions
DPD particles interact via the following force:
where
with
The kernel stem:{w^R} is given by
where \(spow\) is a number between 0 and 1. The default value is 0.25.
25.2. repulsive LJ
Repulsive forces for contact are implemented using the repulsive LJ potential. It is given by
where
for numerical reasons, the magnitude is limited to \(10^4\).
25.3. Host interface
allocate, deallocate the structure:
void pair_ini(PairParams **);
void pair_fin(PairParams *);set parameters:
void pair_set_dpd(int ncol, const float a[], const float g[], float spow, PairParams *p); (1)
void pair_set_lj(float sigma, float eps, PairParams *p); (2)| 1 | set the DPD parameters. ncol is the number of colors. This is
mandatory for any view |
| 2 | set the Lennard-Jones parameters \(\sigma\) and \(\epsilon\). This may be called only when the LJ parameters are needed. |
set parameters from configuration file:
void pair_set_conf(const Config *, const char *name_space, PairParams *);the argument name_space denotes the namespace where to look for the
parameters (see below).
Compute the \(\sigma\) parameter for a given temperature and timestep:
void pair_ini(PairParams **);
void pair_fin(PairParams *);Get the different views:
void pair_get_view_dpd(const PairParams*, PairDPD*);
void pair_get_view_dpd_color(const PairParams*, PairDPDC*);
void pair_get_view_dpd_mirrored(const PairParams*, PairDPDCM*);
void pair_get_view_dpd_lj(const PairParams*, PairDPDLJ*);25.4. device interface
Inside a CUDA kernel, the pairwise force can be called by the generic function
template <typename Param, typename Fo>
_I_ void pair_force(const Param *p, PairPa a, PairPa b, float rnd, /**/ Fo *f)The PairPa structure is a generic particle with color.
This should be used with the parray module.
The Fo structure is a generic force and can be either PairFo or
PairSFo, respectively, for force or force and stress computation.
This should be used with the farray module.
The input parameter Param p is a view for pair parameters.
The above function behaves differently given different types:
-
PairDPD: standard DPD interaction -
PairDPDLJ: standard DPD and repulsive LJ interaction -
PairDPDC: colored DPD interaction: pick up parameters as a function of the particle colors -
PairDPDCM: mirrored DPD: same as colored DPD considering that particlebhas the same color as particlea.
Inside a kernel, the generic force can be added by using
_I_ void pair_add(const PairFo *b, /**/ PairFo *a)
_I_ void pair_add(const PairSFo *b, /**/ PairSFo *a)25.5. Configuration
parameters are configured through 3 namespaces: flu, fsi and
cnt.
example:
flu = {
dpd = true
a = [10.0, 80.0, 10.0]
g = [1.0, 8.0, 15.0]
spow = 0.25
lj = false
}
fsi = {
dpd = true
a = [10.0, 80.0, 10.0]
g = [1.0, 8.0, 15.0]
spow = 0.25
lj = false
}
cnt = {
dpd = true
a = [0.0]
g = [16.0]
spow = 0.25
lj = true
ljs = 0.3
lje = 0.44
}The DPD parameters can be different when many colors are set. User provides parameters in an array following the packed symmetric matrix convention. For example the interaction table for 3 colors
becomes
26. meshbb
Bounce back particles on a moving mesh
Let define the following quantities:
-
\(\mathbf{r}_0, \mathbf{v}_0\) : particle at time \(0\)
-
\(\mathbf{r}_1, \mathbf{v}_1\) : particle at time \(dt\) if there is no collision
-
\(\mathbf{r}_n, \mathbf{v}_n\) : particle at time \(dt\) after bounce back
-
\(h \in [0, dt\)] : collision time
-
\(\mathbf{r}_w, \mathbf{v}_w\) : collision position and velocity of the surface
A particle colliding with a surface is bounced back as:
This module computes the collision time, position and velocity for a moving triangle. The motion of the triangle points are assumed to be linear:
26.1. interface
Allocate and deallocate MeshBB structure:
void mesh_bounce_ini(int maxpp, /**/ MeshBB **d);
void mesh_bounce_fin(/**/ MeshBB *d);Bouncing particles on a set of mesh:
void mesh_bounce_reini(int n, /**/ MeshBB *d); (1)
void mesh_bounce_find_collisions(float dt, int nm, MeshInfo meshinfo, const Positioncp *i_rr, int3 L,
const int *starts, const int *counts, const Particle *pp, const Particle *pp0, /**/ MeshBB *d); (2)
void mesh_bounce_select_collisions(int n, /**/ MeshBB *d); (3)
void mesh_bounce_bounce(float dt, float mass, int n, const MeshBB *d, MeshInfo meshinfo,
const Positioncp *i_rr, const Particle *pp0, /**/ Particle *pp, Momentum *mm); (4)| 1 | reinitialise the structure (must be done before a new time step) |
| 2 | store collision informations inside the structure with a set of mesh. This can be done for multiple mesh sets. |
| 3 | For each bouncing particle, select the collision with minimum time. Must be called after finding all collisions. |
| 4 | bounce particles and store the momentum changes per triangle |
The momentum changes computed above can be collected to rigid objects or to membrane mesh:
void mesh_bounce_collect_rig_momentum(int ns, MeshInfo meshinfo, const Particle *pp, const Momentum *mm, /**/ Rigid *ss); (1)
void mesh_bounce_collect_rbc_momentum(float mass, int nc, MeshInfo mi, const Momentum *mm, /**/ Particle *pp); (2)| 1 | Reduce Momentum array into one force and torque per rigid
object. |
| 2 | Convert momentum information into forces for membrane particles. |
27. Red blood cell
Red blood cell membranes are represented via particles with connectivity.
This module stores the required quantities and functions for:
-
initializing red blood cells positions and orientations
-
managing particles and connectivity
-
membrane force computations
27.1. Elastic energies
27.1.1. spring
Spring energy is a function of distance between connected beads \(r\)
where worm-like chain energy:
and power-law energy:
\(l_0\) is an equilibrium lenght, \(l_{max}\) is a maximum lenght \(l_{max} = l_{0} / x_{0}\), and \(k_p\) is defined from condition that \(U_{spring}\) has a maximum at \(r = l_0\), and \(m\) is a power factor.
27.1.2. local area constrain
For every triangle with area \(A^{loc}\) and an equilibrium area \(A_0^{loc}\)
27.1.3. total area constrain
For whole mesh with area \(A^{tot}\) and an equilibrium area \(A_0^{tot}\)
27.1.4. total volume constrain
For whole mesh with volume \(V\) and an equilibrium volume \(V_0\)
27.1.5. bending
\(\theta\) is an angle between triangles with common edge, \(\theta_0\) is an equilibrium angle.
27.2. Quantities
RbcQuants structure contains particles of membrane and connectivity.
struct RbcQuants {
int n, nc; /* number of particles, cells */
int nt, nv; /* number of triangles and vertices per mesh */
int md; /* maximum valence of the mesh */
Particle *pp, *pp_hst; /* vertices particles on host and device */
bool ids; /* global ids active ? */
int *ii; /* global ids on host */
AreaVolume *area_volume; /* to compute area and volume */
};The above data structure is allocated and freed using:
void rbc_ini(long maxnc, bool ids, const MeshRead*, RbcQuants*);
void rbc_fin(RbcQuants*);The generation is made in two stages: mesh generations and other quantities (global ids). This allows to remove red blood cells colliding with other entities before creating global ids.
void rbc_gen_mesh(const Coords*, MPI_Comm, const MeshRead*, const char *ic, /**/ RbcQuants*); (1)
void rbc_gen_freeze(MPI_Comm, /**/ RbcQuants*); (2)
void rbc_strt_quants(MPI_Comm, const MeshRead*, const char *base, const char *name, const int id, RbcQuants*); (3)
void rbc_strt_dump(MPI_Comm, const char *base, const char *name, int id, const RbcQuants *q); (4)| 1 | Generate mesh from file "ic" (see [mesh_gen]) |
| 2 | Generate global ids of rbc |
| 3 | Generate quantities from restart |
| 4 | Dump a restart state of the quantities |
Available mesh are stored in src/data/cells
27.3. Submodules
27.3.1. adj: mesh adjacency structure
Consider closed triangulated mesh with nv vertices. Degree of a
vertex is the number of edges incident to the vertex. Let md is a
maximum degree of the vertices. There are three types of forces: edge
forces which depend on two vertices, triangle forces which depend on
three vertices, and dihedral forces which depend of four vertices
(edge and two adjusting triangles). To compute forces in one membrane
uDeviceX launches nv * md threads, each thread adds forces to only
one vertices. Adj_v has an API call which allows for a given thread
ID to find which vertices should be used in forces computation.
static __device__ int adj_get_map(int i, Adj_v *adj, /**/ AdjMap *m) {If md * nv is bigger than the number of edges in the membrane and
some threads are not needed. The function returns 0 in this case.
AdjMap is a structure which contains five indices and an ID of the
mesh:
struct AdjMap {
int i0, i1, i2, i3, i4;
int rbc;
};Each thread adds force to a vertices with index 0. It considers edge
01, triangle 012, and two dihedrals 0124 and 1203. For
example, a contribution of edge force 01 to vertex 1 is added by
another thread.
Adj_v is initilized from a host structure Adj:
void adj_ini(int md, int nt, int nv, const int4 *tt, /**/ Adj**);
void adj_fin(Adj*);
int adj_get_map(int i, const Adj*, /**/ AdjMap *m);
int adj_get_max(const Adj*);
void adj_get_anti(const Adj*, /**/ int *anti);
void adj_view_ini(const Adj*, Adj_v**);
void adj_view_fin(Adj_v*);Adj can be used to pack data which can be asseced on device:
float *A;
n = adj_get_max(adj);
EMALLOC(n, &A);
for (i = 0; i < n; i++) {
valid = adj_get_map(i, adj, /**/ &m);
if (!valid) continue;
i0 = m.i0; i1 = m.i1; i2 = m.i2;
A[i] = some_function_of(i0, i1, i2)
}27.3.2. com: center of mass
Compute position and velocity of each mesh of the membrane.
void rbc_com_ini(int nv, int nm_max, /**/ RbcCom**);
void rbc_com_fin(/**/ RbcCom*);
void rbc_com_apply(RbcCom*, int nm, const Particle*, /**/ float3 **rr, float3 **vv);max_nm is a maximum allowed number of meshes. It is a runtime error
if nm exceeds nm_max.
27.3.3. Forces
Model
The membrane forces are computed by differentiating the membrane energy with respect to position:
spring
A force between two connected beads. \(l_0\) is an equilibrium spring lenght, \(l_{max}\) is a maximum spring lenght \(l_0 = l_0 / x_0\).
A force between neighboring consissts of repulsive worm-like-chain part
and attractive power law part
Other forces
(from rnd)
g = gammaC; T = kBT0 f0 = sqrtf(2*g*T/dt)*rnd
TODO
interface
Helpers are stored in RbcForce structure.
Informations about stress free state and random forces are stored
inside.
Allocate, deallocate structure:
void rbc_force_ini(const MeshRead*, RbcForce**);
void rbc_force_fin(RbcForce*);The following setters must be called before force computation:
void rbc_force_set_stressful(int nt, float totArea, /**/ RbcForce*); (1)
void rbc_force_set_stressfree(const char *fname, /**/ RbcForce*); (2)
void rbc_force_set_rnd0(RbcForce*); (3)
void rbc_force_set_rnd1(int seed, RbcForce*); (4)
void rbc_force_set_bending(const MeshRead*, const char*, RbcForce*);| 1 | set stressful state: (no stress free shape) |
| 2 | set stressfree shape from file fname |
| 3 | disable random forces |
| 4 | enable random forces |
Alternatively, user can set the above options through configuration file:
void rbc_force_set_conf(const MeshRead*, const Config *cfg, const char *name, RbcForce*);The forces are computed by calling:
void rbc_force_apply(RbcForce*, const RbcParams*, float dt, const RbcQuants*, /**/ Force*); (1)
void rbc_force_stat(/**/ float *pArea, float *pVolume); (2)| 1 | compute forces |
| 2 | report statistics |
27.3.4. force/area_volume: area and volume
Compute area and volume for every object.
void area_volume_ini(int nv, int nt, const int4 *tt, int max_cell, AreaVolume**); (1)
void area_volume_fin(AreaVolume*);
void area_volume_compute(AreaVolume*, int nm, const Particle*, /**/ float **av); (2)
void area_volume_host(AreaVolume*, /**/ float **av); (3)| 1 | initialization, nv, nt, tt: number of vertices, number of
triangles, a triangle structure on host, max_nm is a maximum
allowed number of meshes |
| 2 | compute area and volume for every mesh, nm is a number of meshes,
output av is a devices array in the form area[0] volume[0] … area[nc-1] volume[nc-1] |
| 3 | after area_volume_compute call, area_volume_host returns a
host version of av array |
27.3.5. force/rnd: random generator
Device random number generator for random forces in rbc
allocate, deallocate structure:
void rbc_rnd_ini(int n, long seed, RbcRnd**);
void rbc_rnd_fin(RbcRnd*);The seed can be set from timeby passing the special value:
enum {SEED_TIME = -1}; /* magic seed: ini from "time" */Random number generation is clled as follows:
void rbc_rnd_gen(RbcRnd*, int n, /**/ float**); (1)
float rbc_rnd_get_hst(const RbcRnd*, int i); (2)| 1 | generate n random numbers on device |
| 2 | get a single random number on host (debug purpose) |
27.3.6. params: rbc parameters
Parameters for the membrane forces.
Consists of two structures: RbcParams (hidden, on host) and
RbcParams_v (view, to be passed to kernels).
RbcParams are allocated and freed with
void rbc_params_ini(RbcParams **);
void rbc_params_fin(RbcParams *);The parameters can be set manually with:
void rbc_params_set_fluct(float gammaC, float gammaT, float kBT, RbcParams *);
void rbc_params_set_bending(float kb, float phi, RbcParams *);
void rbc_params_set_spring(float ks, float x0, float mpow , RbcParams *);
void rbc_params_set_area_volume(float ka, float kd, float kv, RbcParams *);
void rbc_params_set_tot_area_volume(float totArea, float totVolume, RbcParams *);or via the configuration file:
void rbc_params_set_conf(const Config *c, const char *name, RbcParams *);Parameters are accessible via getter functions:
double rbc_params_get_tot_volume(const RbcParams *);The view structure can be created with:
RbcParams_v rbc_params_get_view(const RbcParams *);27.3.7. shape
Helper for stress free state. Compute membrane quantities on host.
Allocate, deallocate structure:
void rbc_shape_ini(const Adj*, const float *rr, /**/ RbcShape**);
void rbc_shape_fin(/**/ RbcShape*);where the positions rr are stored in a AoS fashion x0 y0 z0 x1 y1
z1 …. Also needs adjacency structure as input.
Compute quantities (on host):
void rbc_shape_edg (RbcShape*, /**/ float**); (1)
void rbc_shape_area(RbcShape*, /**/ float**); (2)
void rbc_shape_total_area(RbcShape*, /**/ float*); (3)
void rbc_shape_total_volume(RbcShape*, /**/ float*); (4)| 1 | compute edge lengths (order: see Adj module |
| 2 | compute area of triangles |
| 3 | compute total area |
| 4 | compute total volume |
27.3.8. stretch RBC
Apply a constant force to every vertex of every cell. The force is
configured from the file path.
Format of the data file:
fx0 fy0 fz0 fx1 fy1 fz1 ... fx_nv fy_nv fz_nv
nv is the number of vertices.
void rbc_stretch_ini(const char *path, int nv, /**/ RbcStretch**); /* `nv` is for error check */
void rbc_stretch_fin(RbcStretch*);
void rbc_stretch_apply(int nm, const RbcStretch*, /**/ Force*);28. rig: rigid objects
Rigid objects consist of frozen particles moving in a rigid fashion. Interactions with other objects are modeled via pairwise interactions with the frozen particles.
Rigid objects also contain a surface representation on which other particles may bounce back.
Rigid objects are numbered and need a unique id for dumping diagnosis.
28.1. Quantities
28.1.1. data structure
RigidQuants structure contains particles of rigid objects as well as
mesh particles.
Solid structures contain center of mass, orientation, angular and
linear velocity of the rigid object.
struct RigQuants {
int n, ns, nps; /* number of particles (total), solid, particle per solid */
Particle *pp_hst, *pp; /* particles on hst and device */
Rigid *ss_hst, *ss; /* rigid strutures */
float *rr0_hst, *rr0; /* frozen particle templates */
/* mesh related quantities */
int nt, nv; /* number of [t]riangles and [v]ertices */
int4 *dtt; /* triangle indices on device */
float *dvv; /* vertices on device (template) */
Particle *i_pp_hst, *i_pp; /* particles representing all meshes of all solids of that node */
Rigid *ss_dmp;
long maxp; /* maximum particle number */
};28.1.2. Interface
allocate and deallocate the quantities:
void rig_ini(long maxs, long maxp, const MeshRead*, RigQuants*);
void rig_fin(RigQuants *q);maxp is the maximum particle number per node.
Rigid bodies generation is performed in two stages: create the mesh, then create the rigid particle template, properties and global ids. This allows to remove rigid bodies colliding with other entities before the second phase. The interface for generation is:
void rig_gen_mesh(const Coords*, MPI_Comm, const MeshRead*, const char *ic, /**/ RigQuants *); (1)
void rig_gen_freeze(const Coords*, bool empty_pp, int numdensity, float rig_mass, const RigPinInfo*,
MPI_Comm, const MeshRead*, Particle *opp, int *on, RigQuants *q); (2)
void rig_strt_quants(MPI_Comm, const MeshRead*, const char *base, const char *name, const int id, RigQuants *q); (3)| 1 | generate the meshes from file ic (see [mesh_gen]) |
| 2 | generate particle template, global ids and properties of rigid objects given mesh. This operation will kill solvent particles inside the rigid objects |
| 3 | generate quantities from restart files |
Restart files are dumped using the following functions (see restart):
void rig_strt_dump_templ(MPI_Comm, const char *base, const char *name, const RigQuants *q); (1)
void rig_strt_dump(MPI_Comm, const char *base, const char *name, const int id, const RigQuants *q); (2)| 1 | to be called only once: dump the frozen particle in local referential (common to every rigid objects) |
| 2 | dump Solid structures, describing position, orientation and velocity of the rigid objects |
28.2. update
Position and velocities of rigid objects are updated from forces exerted on the particles.
28.2.1. pin info
The hidden structure RigPinInfo is used to store information about
constrained rigid motion.
This can be used to disable the movement of the center of mass of the rigid object along
\(x, y\) or \(z\) axis (see com parameter).
User can also block the rotation along one of the axes (see axis
parameter).
example:
-
rigid object can rotate but is only able to move along the \(x\) axis:
com = {0, 1, 1}
axis = {0, 0, 0}
-
rigid object can only rotate along the \(z\) axis and its center of mass is not able to move:
com = {1, 1, 1}
axis = {1, 1, 0}
void rig_pininfo_ini(RigPinInfo **); (1)
void rig_pininfo_fin(RigPinInfo *); (2)
void rig_pininfo_set(int3 com, int3 axis, RigPinInfo *); (3)
void rig_pininfo_set_pdir(int pdir, RigPinInfo *); (4)
void rig_pininfo_set_conf(const Config *cfg, const char *ns, RigPinInfo *); (5)
int rig_pininfo_get_pdir(const RigPinInfo *); (6)| 1 | allocate the hidden structure |
| 2 | deallocate the hidden structure |
| 3 | set the motion constrains |
| 4 | for periodic objects, set the direction of periodicity (e.g. cylinder) |
| 5 | set the above parameters from configuration file |
| 6 | get the perioid direction |
The periodic direction can be 0, 1 or 2 for the \(x, y\) or \(z\) axis, respectively. Default value for no periodicty is set via
enum {NOT_PERIODIC = -1};The configuration has the following syntax:
rig = {
pin_com = [0, 0, 0]
pin_axis = [0, 0, 0]
pdir = -1
}28.2.2. interface
naming:
-
ns: number of rigid objects -
ss: array of rigid structuresSolid -
rr0: positions of the rigid particles in the rigid object reference frame -
nps: number of rigid particle per rigid object
void rig_reinit_ft(const int ns, /**/ Rigid *ss); (1)
void rig_update(const RigPinInfo *pi, float dt, int n, const Force *ff, const float *rr0, int ns, /**/ Particle *pp, Rigid *ss); (2)
void rig_generate(int ns, const Rigid *ss, int nps, const float *rr0, /**/ Particle *pp); (3)
void rig_update_mesh(float dt, int ns, const Rigid *ss, int nv, const float *vv, /**/ Particle *pp); (4)| 1 | set the force and torque to 0 |
| 2 | update particle and rigid objects positions and velocity |
| 3 | generate rigid particles from template positions and rigid structures |
| 4 | update the mesh position |
28.3. Submodules
28.3.1. gen
helper to generate rigid particles from solvents and compute rigid properties
The solvent particles inside the given rigid objects are removed by this operation.
void rig_gen_from_solvent(const Coords*, MPI_Comm, RigGenInfo, /*io*/ FluInfo, /**/ RigInfo);To avoid long argument list, the data is packed in helper structures:
struct RigGenInfo {
float mass;
int numdensity;
const RigPinInfo *pi;
int nt, nv;
const int4 *tt; /* on device */
const Particle *pp; /* on device */
bool empty_pp;
const MeshRead *mesh;
};
struct FluInfo {
Particle *pp;
int *n;
};
/* everything on host */
struct RigInfo {
int ns, *nps;
float *rr0;
Rigid *ss;
Particle *pp;
};29. scheme
time stepping scheme related modules
29.1. body forces
Force applied to every particles with active flag push.
It is defined by two structures:
-
BForce, contains all informations needed for the force field. It is hold and maintained on host. -
BForce_v(BForce view), containing only the information needed at a specific time. It is passed to device kernels.
29.1.1. interface
allocate/deallocate the structure:
void bforce_ini(BForce **p);
void bforce_fin(BForce *p);initialize to a given force function:
void bforce_set_none(/**/ BForce *p); (1)
void bforce_set_cste(float3 f, /**/ BForce *p); (2)
void bforce_set_dp(float a, /**/ BForce *p); (3)
void bforce_set_shear(float a, /**/ BForce *p); (4)
void bforce_set_rol(float a, /**/ BForce *p); (5)
void bforce_set_rad(float a, /**/ BForce *p); (6)| 1 | no force |
| 2 | constant force f |
| 3 | double poiseuille |
| 4 | shear |
| 5 | 4 roller mill |
| 6 | radial force |
initialize from configuration:
void bforce_set_conf(const Config *cfg, /**/ BForce *bf);interface:
void bforce_adjust(float3 f, /**/ BForce *fpar); (1)
void bforce_apply(const Coords *c, float mass, const BForce *bf, int n, const Particle *pp, /**/ Force *ff); (2)| 1 | change value of the force |
| 2 | apply body force to particles |
29.1.2. configuration
none
no body force (default value)
bforce = {
type = "none"
}constant
constant force
bforce = {
type = "constant"
f = [1.0, 0.0, 0.0]
}double poiseuille
fx = y > yc ? a : -a
bforce = {
type = "double_poiseuille"
a = 1.0
}shear
fx = a * (y - yc)
bforce = {
type = "shear"
a = 1.0
}4 roller mill
f.x = 2*sin(x)*cos(y) * a;
f.y = -2*cos(x)*sin(y) * a;
while x and y are coordinates relative to the domain center and
normalized to have x = Pi and x = -Pi at the domain edges.
bforce = {
type = "four_roller"
a = 1.0
}radial
fr = a * er / r, where fr is radial force, er is unit radial
vector at position r and r is radial position.
bforce = {
type = "rad"
a = 1.0
}29.2. move
update particles positions and velocities given forces. Currently implemented:
-
Forward Euler
-
Velocity-Verlet
void scheme_move_apply(float dt, float mass, int n, const Force*, Particle*); (1)
void scheme_move_clear_vel(int n, Particle*); (2)| 1 | apply one step of the time scheme to the particles |
| 2 | set velocity of particles to 0 |
29.3. restrain
Restrain the movement of drop or rbc membrane by shifting center of mass velocity.
Consider a subset of particles \(P\) with indices \(I \subset \{i\}_{i = 1}^{n}\).
The Restrain module shifts the center of mass velocity of \(P\) such that
The subset \(I\) depends on the colors of the solvent in case of a single drop.
29.3.1. interface
allocate and free host structure:
void scheme_restrain_ini(Restrain**);
void scheme_restrain_fin(Restrain*);Set parameters:
void scheme_restrain_set_red(Restrain*); (1)
void scheme_restrain_set_rbc(Restrain*); (2)
void scheme_restrain_set_none(Restrain*); (3)
void scheme_restrain_set_freq(int freq, Restrain*); (4)| 1 | Set to restrain the "red" solvent only |
| 2 | Set to restrain the rbc membrane only |
| 3 | Set for no restrain |
| 4 | Set the diagnosis frequency (0 for no diagnosis) |
Set parameters from configuration file:
void scheme_restrain_set_conf(const Config*, Restrain*);Apply restrain (note: this calls collective mpi operation):
void scheme_restrain_apply(MPI_Comm comm, const int *cc, long it, /**/ Restrain *r, SchemeQQ qq);29.3.2. configuration
restrain = {
kind = ["none", "red", "rbc"]
freq = 1000;
}29.4. Time line
Manage simulation time.
Allocate, deallocate structure:
void time_line_ini(float start, /**/ TimeLine**);
void time_line_fin(TimeLine*);Manipulate time:
void time_line_advance(float dt, TimeLine*); (1)
int time_line_cross(const TimeLine*, float interval); (2)| 1 | advance time by dt (should be called at every time step) |
| 2 | return true if there exist integer n such that n*interval
is in between current and previous times, in other words has the
simulation just crossed n*interval for some n. |
Getters:
float time_line_get_current (const TimeLine*); (1)
long time_line_get_iteration(const TimeLine*); (2)| 1 | get current time |
| 2 | get iteration id |
The time structure can also be initialised via restart mechanism:
void time_line_strt_dump(MPI_Comm, const char *base, int id, const TimeLine*); (1)
void time_line_strt_read(const char *base, int id, TimeLine*); (2)| 1 | dump time line state to a restart file in text format |
| 2 | read restart file to initialize time line state |
29.5. Time step
Time step manager.
Two possible modes:
-
const: constant timestep -
disp: adaptive time step based on the maximum acceleration of given particles
29.5.1. interface
allocate, deallocate the object:
void time_step_ini(const Config*, /**/ TimeStep**); (1)
void time_step_fin(TimeStep*);| 1 | The mode is initialised from configuration file. See Configuration for syntax. |
float time_step_dt(TimeStep*, MPI_Comm, TimeStepAccel*); (1)
float time_step_dt0(TimeStep*); (2)
void time_step_log(TimeStep*); (3)| 1 | Compute and return current timestep depending on the mode.
See acceleration manager for ImeStepAccel argument. |
| 2 | return previous timestep |
| 3 | print time step informations to screen |
29.5.2. acceleration manager
Helper structure to pack multiple arrays of acceleration
allocate, deallocate the structure:
void time_step_accel_ini(/**/ TimeStepAccel**);
void time_step_accel_fin(TimeStepAccel*);interface:
void time_step_accel_push(TimeStepAccel*, float m, int n, Force*); (1)
void time_step_accel_reset(TimeStepAccel*); (2)| 1 | add an array of forces. m is the mass of the particles. |
| 2 | remove all pushed arrays |
29.5.3. Configuration
constant timestep dt = 1e-3 (no log):
time = {
type = "const"
dt = 1e-3
screenlog = false
}adaptive timestep with maximum dt = 1e-2 and maximum displacement
dx = 0.1 (active log):
time = {
type = "disp"
dt = 1e-2
dx = 0.1
screenlog = true
}30. sim: simulation
manages all modules together to run a simulation
30.1. interface
Allocate and deallocate the structure
void sim_ini(const Config*, MPI_Comm, /**/ Sim**);
void sim_fin(Sim*);Run simulation:
void sim_gen(Sim*); (1)
void sim_strt(Sim*); (2)| 1 | run from scratch: this will generate all quantities in two stages (solvent only, equilibrating; freezing stage, adding walls and solutes) |
| 2 | run from restart files |
30.2. submodules
30.2.1. objects
Manages all solutes objects. This includes rigid objects and membranes.
Interface
Allocate, deallocate the structure:
void objects_ini(const Config*, const Opt*, MPI_Comm, const Coords*, int maxp, Objects**);
void objects_fin(Objects*);Generate the quantities:
void objects_gen_mesh(Objects*); (1)
void objects_remove_from_wall(const Sdf *sdf, Objects *o); (2)
void objects_gen_freeze(PFarray*, Objects*); (3)| 1 | Generate the meshes of all objects from the template mesh and an initial condition files (see [mesh_gen]) |
| 2 | Remove all meshes colliding with walls |
| 3 | Build all remaining quantities after removal from walls. The rigid objects need solvent particles |
The quantities can be instead generated from restart files:
void objects_restart(Objects*);The state of the objects can be dumped using
void objects_mesh_dump(Objects*); (1)
void objects_diag_dump(float t, Objects*); (2)
void objects_part_dump(long id, Objects*, IoBop*); (3)
void objects_strt_templ(const char *base, Objects*); (4)
void objects_strt_dump(const char *base, long id, Objects*); (5)| 1 | Dump all meshes of objects |
| 2 | Dump diagnosis. This include the solid objects dumps and the membrane centers of mass. |
| 3 | Dump rigid particles in bop format |
| 4 | Dump rigid templates to restart files |
| 5 | Dump current state to restart files |
The objects are updated using
void objects_clear_vel(Objects*); (1)
void objects_advance(float dt, Objects*); (2)
void objects_distribute(Objects*); (3)
void objects_update_dpd_prms(float dt, float kBT, Objects*); (4)| 1 | set all velocities to 0 |
| 2 | advance objects for one timestep; internal fast forces are computed there for time separation scheme of membranes |
| 3 | redistribute objects accross nodes |
| 4 | update dpd parameters given a new time step |
The objects forces can be managed by calling
void objects_clear_forces(Objects*); (1)
void objects_body_forces(const BForce*, Objects *o); (2)| 1 | set all forces to 0 |
| 2 | apply body forces to the objects |
The internal membrane forces are computed inside advance (see above).
Other forces can be set via the getter functions (see link with objinter : object interactions):
bool objects_have_bounce(const Objects*);
void objects_get_particles_all(Objects*, PFarrays*); (1)
void objects_get_particles_mbr(Objects*, PFarrays*); (2)
void objects_get_accel(const Objects*, TimeStepAccel*); (3)
void objects_get_params_fsi(const Objects*, const PairParams*[]); (4)
void objects_get_params_adhesion(const Objects*, const PairParams*[]); (5)
void objects_get_params_repulsion(const Objects*, const WallRepulsePrm*[]); (6)
void objects_get_params_cnt(const Objects*, const PairParams***); (7)| 1 | get particle infos of all objects |
| 2 | get particle infos of membranes |
| 3 | retrieve acceleration infos (see Time step) |
| 4 | get the pair parameters for fsi interactions (one per object, NULL for no interactions) |
| 5 | get the parameters for adhesion interactions with walls (one per object, NULL for no interactions) |
| 6 | get the parameters for repulsion with walls (one per object, NULL for no interactions) |
| 7 | get the pair parameters for cnt interactions (one per object pair, NULL for no interactions) |
void objects_activate_mbr_bounce(Objects*);
void objects_bounce(float dt, float flu_mass, const Clist *flu_cells, long n, const Particle *flu_pp0, Particle *flu_pp, Objects *obj); (1)
void objects_recolor_flu(Objects*, PFarray *flu); (2)
double objects_mbr_tot_volume(const Objects*); (3)| 1 | bounce solvent particles against objects |
| 2 | recolor solvent particles located inside membranes |
| 3 | compute the total volume occupied by all membranes |
30.2.2. objinter : object interactions
Helper to manage interactions between objects (contact forces) and interactions with solvent particles (fsi forces).
Allocate, deallocate the structure:
void obj_inter_ini(const Config*, const Opt*, MPI_Comm, float dt, int maxp, /**/ ObjInter**);
void obj_inter_fin(ObjInter*);Interface:
void obj_inter_forces(ObjInter*, const PairParams **fsi_prms, const PairParams **cnt_prms, PFarray *flu, const int *flu_start, PFarrays *obj); (1)| 1 | compute interactions (contact and fsi), bulk and halo |
30.2.3. walls
Helper to manage solid walls.
Allocate, deallocate the structure:
void wall_ini(const Config*, int3 L, Wall**);
void wall_fin(Wall*);Generate from solvent particles:
void wall_gen(MPI_Comm, const Coords*, OptParams, bool dump_sdf,
/*io*/ int *n, Particle *pp, /**/ Wall*);Alternatively, can be generated from restart files:
void wall_restart(MPI_Comm, const Coords*, OptParams, bool dump_sdf,
const char *base, /**/ Wall*);The restart file is dumped by calling
void wall_dump_templ(const Wall*, MPI_Comm, const char *base);Interactions with other quantities are possible with the functions
void wall_interact(const Coords*, const PairParams*[], Wall*, PFarrays*);
void wall_adhesion(const Coords*, const PairParams*[], Wall*, PFarrays*);
void wall_bounce(const Wall*, const Coords*, float dt, PFarrays*);
void wall_repulse(const Wall*, const WallRepulsePrm *[], PFarrays*);The wall velocity can be updated in time with
void wall_update_vel(float t, Wall *);Getter functions:
void wall_get_sdf_ptr(const Wall*, const Sdf**); (1)
double wall_compute_volume(const Wall*, MPI_Comm, int3 L); (2)| 1 | get a pointer to sdf: signed distance function object |
| 2 | compute the volume inside the walls (where the solvent can be located). This is evaluated via Monte Carlo |
31. sdf: signed distance function
The Signed Distance Function (SDF) \(S(x, y, z)\) is used to give the distance from a given position to the wall. The sign of the SDF field tells if the position is inside or outside the wall.
Conventions:
-
\(S(x,y,z) < -1\) : inside domain, far from wall
-
\(S(x,y,z) < 0\) : inside domain
-
\(S(x,y,z) = 0\) : wall interface
-
\(S(x,y,z) > 0\) : inside wall
-
\(S(x,y,z) > 1\) : inside wall, far from surface
Example of sdf function in 2D:
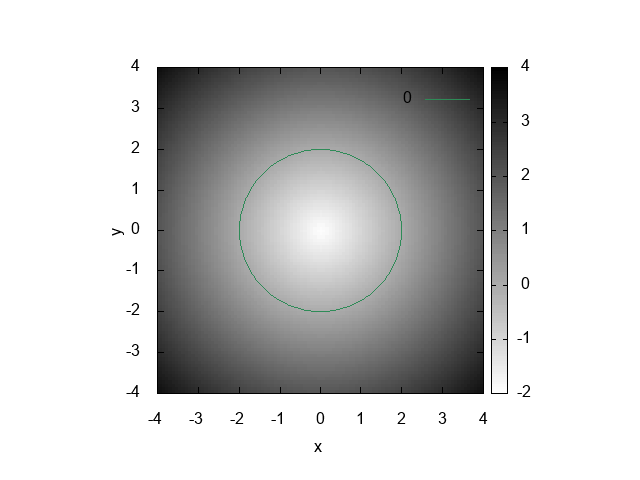
The above example denotes a circular wall of radius 2. The isosurface \(S(x,y,z) = 0\) is located at the wall interface.
31.1. interface
allocate, deallocate the structure:
void sdf_ini(int3 L, Sdf**);
void sdf_fin(Sdf*);interface:
void sdf_gen(const Coords*, MPI_Comm cart, bool dump, Sdf*); (1)
void sdf_get_view(const Sdf*, /**/ Sdf_v*); (2)| 1 | generate the sdf field from file "sdf.dat" |
| 2 | get view to be passed to kernels |
device interface:
_I_ float3 sdf_ugrad(const Sdf_v *texsdf, const float3 *r) (1)
_I_ bool sdf_far(const Sdf_v *sdf, float x, float y, float z) (2)
_I_ float sdf_eval(const Sdf_v *sdf0, float x, float y, float z) (3)| 1 | returns gradient of sdf (normalised) at given position (finite difference) |
| 2 | returns true if position is far inside the domain (approximation) |
| 3 | returns the sdf value at given position (linear interpolation) |
Bounce back from wall:
void sdf_bounce(float dt, const WvelStep*, const Coords*, const Sdf*, int n, /**/ Particle*);Sorting tools:
void sdf_bulk_wall(const Sdf*, /*io*/ int *s_n, Particle *s_pp, /*o*/ int *w_n, Particle *w_pp); (1)
int sdf_who_stays(const Sdf*, int n, const Particle*, int nc, int nv, /**/ int *stay); (2)
double sdf_compute_volume(MPI_Comm, int3 L, const Sdf*, long nsamples); (3)| 1 | extract wall particles from solvent particles. Solvent particles which are not inside the domain are not kept. |
| 2 | label nc objects of nv particles to inside domain or not. |
| 3 | compute the volume between walls using monte carlo
integration. nsamples is the number of samples per subdomain. |
31.2. submodules
Some tasks of the SDF object are splitted into submodules:
31.2.1. array3D
a simple data holder for storing a 3D cuda array scalar field.
data structure
struct Array3d {
cudaArray_t a; (1)
size_t x, y, z; (2)
};| 1 | data on device |
| 2 | grid size |
interface
struct Array3d;
void array3d_ini(Array3d**, size_t x, size_t y, size_t z); (1)
void array3d_fin(Array3d*); (2)
void array3d_copy(size_t x, size_t y, size_t z, float *D, /**/ Array3d*); (3)| 1 | allocate the structure |
| 2 | deallocate the structure |
| 3 | copy data from host to cuda array on device |
31.2.2. bounce
Particles crossing the wall surface are bounced back into the domain. We define:
-
\(\mathbf{r}_0, \mathbf{v}_0\) position and velocity before the particle has crossed the surface
-
\(\mathbf{r}_1, \mathbf{v}_1\) position and velocity after the particle has crossed the surface, not bounced back
-
\(\mathbf{r}_n, \mathbf{v}_n\) position and velocity after bounce-back
-
\(\mathbf{r}_w, \mathbf{v}_w\) position and velocity of the wall at collision point
The collision point is found by solving for the collision time \(h\)
with Newton iterations. We obtain \(\mathbf{r}_w = \mathbf{r}_0 + h \mathbf{v}_0\).
The bounced particle is set to
interface
void bounce_back(float dt, const WvelStep *wv, const Coords *c, const Sdf *sdf, int n, /**/ Particle *pp);31.2.3. field
read and manage a scalar field on host
interface
allocate, deallocate:
void field_ini(const char *path, /**/ Field**); (1)
void field_fin(Field*); (2)| 1 | allocate and read field from file "path" |
| 2 | deallocate the field structure |
getter functions:
void field_size(const Field*, /**/ int N[3]); (1)
void field_extend(const Field*, /**/ float ext[3]); (2)
void field_data(const Field*, /**/ float**); (3)| 1 | get grid size |
| 2 | get extents of the grid |
| 3 | get pointer to data |
void field_sample(const Field*, const Tform*, const int N[3], /**/ Field**); (1)
void field_dump(const Field*, const Coords*, MPI_Comm cart); (2)
void field_scale(Field*, float scale); (3)| 1 | sample field to a new grid size N |
| 2 | dump field to "wall.h5" |
| 3 | scale field by scale |
31.2.4. label
a simple tool to mark particles in wall regions
labels can be:
LABEL_BULK, /* remains in bulk */
LABEL_WALL, /* becomes wall particle */
LABEL_DEEP /* deep inside the wall */void wall_label_dev(const Sdf *sdf, int n, const Particle*, /**/ int *labels); (1)
void wall_label_hst(const Sdf *sdf, int n, const Particle*, /**/ int *labels); (2)| 1 | set labels on an array of particles on device |
| 2 | set labels on an array of particles on host |
31.2.5. tex3D
a simple texture object manager for representing 3d grid scalar field
data structures
struct Tex3d_v { cudaTextureObject_t t; }; (1)
struct Tex3d { cudaTextureObject_t t; }; (2)| 1 | view, to be passed on device |
| 2 | Host structure |
interface
allocate and destroy texture object:
void tex3d_ini(Tex3d**);
void tex3d_fin(Tex3d*);manipulate texture object:
void tex3d_copy(const Array3d*, /**/ Tex3d*); (1)
void tex3d_to_view(const Tex3d*, /**/ Tex3d_v*); (2)| 1 | create texture object from Array3d object |
| 2 | create a view to be passed to kernels |
31.2.6. tform
A simple set of linear transformations for sdf. Based on tform module.
/* T: texture size, N: sdf file size, M: wall margin */
void tex2sdf_ini(const Coords*, const int T[3], const int N[3], const int M[3], /**/ Tform*); (1)
void out2sdf_ini(const Coords*, const int N[3], /**/ Tform*); (2)
void sub2tex_ini(const Coords*, const int T[3], const int M[3], /**/ Tform*); (3)| 1 | transform from texture coordinates to sdf coordinates |
| 2 | transform from Glbal coordinates to sdf coordinates |
| 3 | transform from subdomain coordinates to texture coordinates |
32. Struct: helper structures
Helper structures to pass particle data between modules.
32.1. partlist
Part list: a structure to handle a list of dead or alive particles Purpose: kill particles during redistribution or cell lists build
32.1.1. data structure
struct PartList {
const Particle *pp; /* particles array */
const int *deathlist; /* what pp is dead or alive */
};32.1.2. interface
contains only device interface:
static __device__ bool is_dead(int i, const PartList lp) {
if (lp.deathlist)
return lp.deathlist[i] == DEAD;
return false;
}
static __device__ bool is_alive(int i, const PartList lp) {
return !is_dead(i, lp);
}32.2. parray
Generic particle array to be passed to interaction kernels.
32.2.1. host interface
A PaArray structure can be configured by pushing particles and,
optionally, colors:
void parray_push_pp(const Particle *pp, PaArray *a);
void parray_push_cc(const int *cc, PaArray *a);| Particles must be pushed before colors |
Client can check if the colors has been pushed by calling
bool parray_is_colored(const PaArray *a);The particle array data are meant to be passed to kernels.
In order to inline the fetching mode (see device interface), different
views can be generated from the PaArray structure:
void parray_get_view(const PaArray *a, PaArray_v *v); (1)
void parray_get_view(const PaArray *a, PaCArray_v *v); (2)| 1 | Get a view to fetch particles without colors |
| 2 | Get a view to fetch particles with colors |
32.2.2. device interface
Generic particle (see pair module) can be fetched depending on the view:
_I_ void parray_get(PaArray_v a, int i, /**/ PairPa *p) (1)
_I_ void parray_get(PaCArray_v a, int i, /**/ PairPa *p) (2)| 1 | fetch position and velocity only |
| 2 | fetch position, velocity and color |
32.3. farray
Generic force array to be passed to interaction kernels. Implemented versions:
-
forces only
-
forces and stresses
32.3.1. host interface
A FoArray structure can be configured by pushing forces and,
optionally, stresses:
void farray_push_ff(Force *ff, FoArray *a);
void farray_push_ss(float *ss, FoArray *a);| Forces must be pushed before stresses |
Client can check if the stresses has been pushed by calling
bool farray_has_stress(const FoArray *a);The force array data are meant to be passed to kernels.
In order to inline the forces computations mode (see device interface), different
views can be generated from the FoArray structure:
void farray_get_view(const FoArray *a, FoArray_v *v); (1)
void farray_get_view(const FoArray *a, FoSArray_v *v); (2)| 1 | Get a view to compute forces only |
| 2 | Get a view to compute forces and stresses |
32.3.2. device interface
Generic forces (see pair module) can be added to the generic force array depending on the view type:
template <int S>
_I_ void farray_add(const PairFo *f, int i, /**/ FoArray_v a) (1)
template <int S>
_I_ void farray_add(const PairSFo *f, int i, /**/ FoSArray_v a) (2)| 1 | add forces only to the array |
| 2 | add forces and stresse to the array |
The template parameter S is the sign, must be either -1 or 1.
Note that it only affects the forces, stresses are always added with
positive sign, as opposed to forces.
For equivalent atomic operations, the following functions can be called:
template <int S>
_I_ void farray_atomic_add(const PairFo *f, int i, /**/ FoArray_v a)
template <int S>
_I_ void farray_atomic_add(const PairSFo *f, int i, /**/ FoSArray_v a)The generic Force structure can be initialised to 0 based on the type of the Generic array:
_I_ PairFo farray_fo0(FoArray_v)
_I_ PairSFo farray_fo0(FoSArray_v)33. utils
33.1. utility functions
a set of utility functions
33.1.1. general tools
the following functions are provided in the imp.h header file.
memory management functions:
void emalloc(size_t, /**/ void**); (1)
void efree(void*); (2)
void *ememcpy(void *dest, const void *src, size_t n); (3)| 1 | safe malloc: throws an error on failure |
| 2 | safe free |
| 3 | safe memcpy |
convenient macros for the above functions:
#define EMALLOC(n, ppdata) UC(emalloc((n)*sizeof(**(ppdata)), (void**)(ppdata)))
#define EFREE(pdata) UC(efree(pdata))
#define EMEMCPY(n, src, dest) ememcpy((void*)(dest), (const void*)(src), (n)*sizeof(*(dest)))safe versions of the stdio functions:
void efopen(const char *fname, const char *mode, /**/ FILE**);
void efclose(FILE*);
void efread(void *ptr, size_t size, size_t nmemb, FILE*);
void efwrite(const void *ptr, size_t size, size_t nmemb, FILE*);
void efgets(char *s, int size, FILE*);additional tools:
bool same_str(const char *a, const char *b); (1)
const char* get_filename_ext(const char*);| 1 | returns true if the two strings are the same |
33.1.2. msg: messages
a simple logging tool for many rank application.
a message is printed in the stderr stream by the master rank (rank 0).
all ranks also print the message in file .XXX, where XXX is the
MPI rank id.
void msg_ini(int rank); (1)
void msg_print(const char *fmt, ...); (2)| 1 | initialise the logger |
| 2 | log message. format is the same as printf |
33.1.3. os: operating system tasks
void os_mkdir(const char* path); (1)
long os_time(); (2)
void os_srand(long int seedval); (3)
double os_drand(); (4)
void os_sleep(unsigned int seconds); (5)
void os_malloc_stats(); // TODO| 1 | create a directory |
| 2 | returns local time |
| 3 | seed for os_drand() |
| 4 | returns double random number between 0 and 1 |
| 5 | sleep for seconds seconds |
33.2. error handling
uDeviceX has a primitive error handling mechanism. Error is raised if
-
ERR(fmt, …)is called. Syntax of ERR is the same as one ofprintf(3). -
a function wrapped with
CCreturns a error code -
a function wrapped with
MCreturns a error code
If error is raised the uDeviceX aborts and prints a error message
with a function call trace. Only the function calls wrapped with UC
go into trace. For example,
void c() { ERR("c failed"); }
void b() { UC(c()); }
void a() { UC(b()); }
void main () {
a();
}
produces a log with source file name and line number of two UC calls
and ERR call.
33.3. cc: cuda check
[C]uda [C]heck macro.
Error handling for cuda API calls. usage:
CC(my_cuda_api_call());CC uses internally UdxError in case of failure. This allows to
dump a backtrace (see [error]).
33.4. mc: mpi check
[M]PI [C]heck macro.
Error handling for MPI API calls. usage:
MC(my_mpi_api_call());MC uses internally UdxError in case of failure. This allows to
dump a backtrace (see [error]).
33.5. kl: kernel launch
[K]ernel [L]aunch macro.
a macro for cuds kernel launches
All but unsafe skip kernels with zero thread number.
Examples:
KL(fun, (i+1, j, k), ()) -> fun<<<i+1, j, k>>>()
KL(fun, (i+1, j, k), (a, b)) -> fun<<<i+1, j, k>>>(a, b)33.6. texo: texture object
a simple wrapper for texture objects in cuda.
template<typename T>
struct Texo {
cudaTextureObject_t d;
};on host: create and destroy the texture object of a given type T:
void texo_setup(int n, T *data, /**/ Texo<T> *to)
void texo_destroy(/**/ Texo<T> *to)on device: fetch from texture object:
const T texo_fetch(const Texo<T> t, const int i)34. wall
Manages frozen wall particles data.
34.1. data structure
The data is stored in a visible structure. The user can access directly the fields.
struct WallQuants {
float4 *pp; /* particle positions xyzo xyzo ... */
int n; /* number of particles */
int3 L; /* subdomain size */
};
struct WallTicket;
struct WallRepulsePrm;Only positions of the particles are stored, Their velocity can be computed by using the wvel submodule.
The Ticket hidden structure contains helpers (cell lists, texture objects,
random number generator) for force interactions with external
particles.
34.2. interface
allocate and deallocate the data:
void wall_ini_quants(int3 L, WallQuants*);
void wall_ini_ticket(int3 L, WallTicket**);
void wall_fin_quants(WallQuants*);
void wall_fin_ticket(WallTicket*);generate the quantities:
void wall_gen_quants(MPI_Comm, int numdensity, int maxn, const Sdf*, /* io */ int *o_n, Particle *o_pp, /**/ WallQuants*); (1)
void wall_gen_ticket(const WallQuants*, WallTicket*); (2)| 1 | freeze the particles from a given equilibrated array of solvent particles occupying the subdomain. The input array of particles is resized and only solvent particles remain. Creates additional "margin particles" copied from neighbouring ranks. See exch. |
| 2 | generate Ticket structure from quantities |
restart interface:
void wall_strt_quants(MPI_Comm, const char *base, int maxn, WallQuants*); (1)
void wall_strt_dump_templ(MPI_Comm, const char *base, const WallQuants*); (2)| 1 | read quantities from restart files |
| 2 | dump quantities to restart files (set 0 velocity to particles) |
compute interactions with other particles (see force submodule):
void wall_force(const PairParams*, const WvelStep *, const Coords*, const Sdf*, const WallQuants*,
const WallTicket*, int n, const PaArray*, const FoArray*); (1)
void wall_force_adhesion(const PairParams*, const WvelStep *, const Coords*, const Sdf*, const WallQuants*,
const WallTicket*, int n, const PaArray*, const FoArray*); (2)
void wall_repulse(const Sdf*, const WallRepulsePrm*, long n, const PaArray*, const FoArray*); (3)| 1 | compute pairwise interactions between wall particles and input particles |
| 2 | compute visco elastic interactions with wall particles within cutoff radius 1 |
| 3 | compute field interaction depending on the sdf and input particles |
The repulsion parameters are managed via the following interface:
void wall_repulse_prm_ini(float lambda, WallRepulsePrm**); (1)
void wall_repulse_prm_ini_conf(const Config*, const char *ns, WallRepulsePrm**); (2)
void wall_repulse_prm_fin(WallRepulsePrm*); (3)| 1 | allocate and initialise the parameters |
| 2 | allocate and initialise the parameters from config file |
| 3 | deallocate the parameters |
34.3. submodules
34.3.1. exch
a simple module to exchange the "margin particles" between neighbouring ranks (on host). These particles are used in interactions and act as ghost particles.
interface:
void wall_exch_pp(MPI_Comm cart, int numdensity, int3 L, int maxn, /*io*/ Particle *pp, int *n);maxn is the maximum number of particles that can be stored in the
pp buffer.
34.3.2. force
compute interaction forces between frozen wall particles and other particles.
interface:
void wall_force_apply(const PairParams*, const WvelStep*, const Coords*, const PaArray*, int n, RNDunif*, WallForce,
/**/ const FoArray*); (1)
void wall_force_adhesion_apply(const PairParams*, const WvelStep*, const Coords*, const PaArray*, int n, RNDunif*, WallForce,
/**/ const FoArray*);
void wall_force_repulse(Sdf_v, WallRepulsePrm, long n, const PaArray*, const FoArray*); (2)| 1 | pairwise interactions: input particles with frozen particles |
| 2 | field interaction: input particles get force \(\mathbf{f}(s)\), where \(s\) is the sdf value at position of input particle. |
The helper structure WallForce acts as a view to be passed to
the kernel. It is defined as:
struct WallForce { /* local wall data */
Sdf_v sdf_v;
Texo<int> start;
Texo<float4> pp;
int n;
int3 L;
};The repulsive force \(\mathbf{f}\) is computed as:
where
when \(s>-1\) and 0 otherwise. For \(\lambda = 1\):
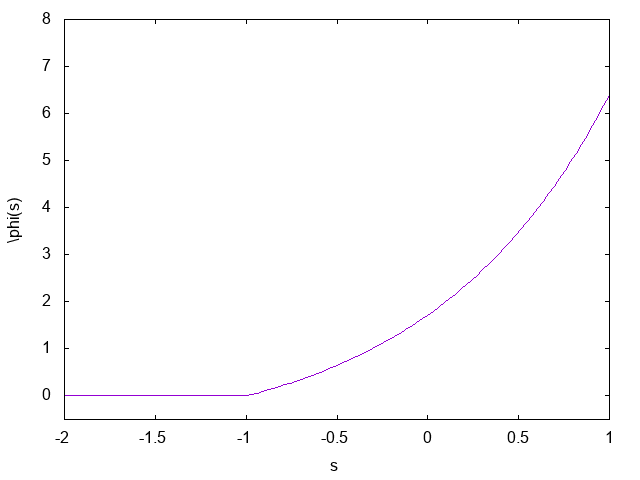
34.3.3. sdf
34.3.4. wvel
Wall velocity field. Used to set velocity to wall particles for wall interactions. Also used to get wall velocity for bounce back on walls
data structures
data structures are separated into 3 kinds of data structures:
-
Wvel(hidden), which contains all informations needed for the velocity field. It is hold and maintained on host. -
WvelStep(hidden), containing only the information needed for one specific time step. It is generated fromWvelstructure. -
Views, passed to kernels. They are generated from the
WvelStepstructure.
interface
Interface is splitted between host and device
Host
Host code is responsible for initialisation of Wvel and convert
Wvel to a view at a given timestep.
alloc, free structures:
void wvel_ini(Wvel **wv);
void wvel_fin(Wvel *wv);
void wvel_step_ini(WvelStep **wv);
void wvel_step_fin(WvelStep *wv);Set velocity type from parameters:
void wvel_set_cste(float3 u, Wvel *vw);
void wvel_set_shear(float gdot, int vdir, int gdir, int half, Wvel *vw);
void wvel_set_shear_sin(float gdot, int vdir, int gdir, int half, float w, Wvel *vw);
void wvel_set_hs(float u, float h, Wvel *vw);
void wvel_set_timestep(float dt, Wvel *vw);Set velocity type from configuration:
void wvel_set_conf(const Config *cfg, Wvel *vw);Get step structure:
void wvel_get_step(float t, const Wvel *wv, /**/ WvelStep *);Get view structures:
void wvel_get_view(const WvelStep *w, /**/ WvelCste_v *v);
void wvel_get_view(const WvelStep *w, /**/ WvelShear_v *v);
void wvel_get_view(const WvelStep *w, /**/ WvelHS_v *v);The convertion to view structures can be dispatch using the type of the parameters:
enum {
WALL_VEL_V_CSTE,
WALL_VEL_V_SHEAR,
WALL_VEL_V_HS,
};which can be retrieved from the Step structure using
int wvel_get_type(const WvelStep *w);Device
Velocity field can be retrieved, depending on the view structure, using
static __device__ void wvel(WvelCste_v p, Coords_v c, float3 r, /**/ float3 *v)
static __device__ void wvel(WvelShear_v p, Coords_v c, float3 r, /**/ float3 *v)
static __device__ void wvel(WvelHS_v p, Coords_v c, float3 r, /**/ float3 *v)Bounce function: gives bounced-back velocity from position and velocity of particle.
template <typename Wvel_v>
static __device__ void bounce_vel(Wvel_v wv, Coords_v c, float3 rw, /* io */ float3* v)Configuration
constant
constant velocity \(u = (1, 0, 0)\):
wvel = {
type = "constant"
u = [1.0, 0.0, 0.0]
}shear
shear velocity \(u = (3 y, 0, 0)\):
wvel = {
type = "shear"
gdot = 3.0
vdir = 0
gdir = 1
half = 0
}sinusoidal shear
shear velocity \(u(t) = (3 y \sin(5 t), 0, 0)\):
wvel = {
type = "shear sin"
gdot = 3.0
vdir = 0
gdir = 1
w = 5.0
}Hele Shaw
velocity \(u_r = \frac u r \left(1 - \frac {4 z^2}{h^2}\right)\):
wvel = {
type = "hele shaw"
u = 1.0
h = 8.0
}35. third party dependencies
35.1. nvcc
35.2. MPI library
To get the flags
mpicxx -show
or
pkg-config --libs mpich
35.3. libconfig
35.3.1. from source
v=1.7.1
wget https://hyperrealm.github.io/libconfig/dist/libconfig-$v.tar.gz
tar zxvf libconfig-$v.tar.gz
cd libconfig-$v
./configure --prefix=${HOME}/prefix/libconfig --disable-cxx
make -j
make install35.3.2. from git
git clone git@github.com:hyperrealm/libconfig.git
cd libconfig
autoreconf
./configure --prefix=${HOME}/prefix/libconfig --disable-cxx
make -j
make install35.3.3. from apt
sudo apt install libconfig-dev35.3.4. pkgconfig
add path for pkg config
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:$HOME/prefix/libconfig/lib/pkgconfig35.4. hdf5
a data model, library, and file format for storing and managing data
To get the compilation and linking flags
h5c++ -showor
pkg-config hdf5-mpich --libsTo build from the source
Configuration options
./configure --prefix=$HOME/prefix/hdf5 --enable-parallel CXX=mpic++ CC=mpicc35.5. bop
a simple format for particle data, see bop.
installation:
git clone git@github.com:amlucas/bop.git
cd bop
./configure [OPTIONS] (1)
make
make -s test| 1 | see ./configure --help |
36. wrappers
36.1. intro
u.run respects several environment variables to modify the way udx
is run
36.2. MEM
if MEM is set udx is ran with cuda-memcheck and MEM is used as a
list of parameters
MEM= u.test test/* MEM='--leakcheck --blocking' u.test test/* MEM='--tool initcheck' u.test test/*
see also poc/memcheck
36.3. VAL
if VAL is set udx is ran with valgrind and VAL is used as a list
of parameters.
VAL= u.test test/* VAL="--leak-check=full --show-leak-kinds=all" u.test test/*
u.run respect DRYRUN : only show the commands do not execute them
DRYRUN= VAL=--option u.run ./udx module: load cray-hdf5-parallel cudatoolkit daint-gpu cmd: srun -n 1 -u valgrind --option ./udx
36.4. PROF
if PROF is set is ran with nvprof
PROF="--export-profile main.prof" u.run ./udx nvprof -i main.prof
See also poc/ppbandwidth
36.5. TIM
if TIM is set is ran with time